
教師なし形態素解析で頻出語を可視化する
概要
- NPYLMでワードクラウドを作る
ワードクラウドとは
Twitterで以下のような投稿を見たことがあるかもしれません。
これはワードクラウドと呼ばれるもので、クロクモなどのwebサービスで作ることができます。
ワードクラウドは頻出語をその頻度に応じたサイズで並べることで分かりやすく可視化することができますが、こういったwebサービスは基本的には可視化部分をamueller氏のword_cloudで行い、頻出語のカウントにはMeCabを用いた形態素解析により行っています。
教師なし形態素解析とは
MeCabによる形態素解析は基本的に単語辞書を用いて行われます。
それに対し教師なし形態素解析は与えられた文字列の集合からMCMCと動的計画法によりNPYLMと呼ばれる言語モデルを学習し、得られたモデルをもとに文を単語に分割することができます。
特徴としてどのような文字列からも単語を推定することができるため、分かち書きが必要なあらゆる言語はもちろん、ヴォイニッチ手稿やロンゴロンゴなどの未解読の言語であろうと関係なく単語分割を行うことができます。
ただしMeCabとは違い品詞は取れません。
教師なし形態素解析でワードクラウドを作る
NPYLMは頻度のカウントによる離散分布を扱っているため、得られたモデルの単語ユニグラムには全ての単語の頻度が記録されています。
そこで今回はワードクラウドの対象となる文集合に対してNPYLMを学習させ、単語ユニグラムノードを参照して頻度の高い単語を可視化することにします。
しょこたんブログ
独特の言い回しや顔文字を多用するために形態素解析が困難だそうです。(たまに研究の評価実験に使われています)
テキストデータの収集のやりやすさからアメブロではなくhttp://simplog.jp/top/10893446から収集しました。
9,027行、274,534文字からなるコーパスを構築しNPYLMを学習させました。

「ありがとうございマミタス」という表現を多用するため「ありがとうござい」という一見中途半端な切れ方の単語が出てきています。
ちなみにマミタスは飼い猫の名前です。
市況
2ちゃんねるの市況板のドル円スレからレスを抽出し、8,395行、146,130文字のコーパスを作成しました。
前処理として全ての数字を#に置き換えています

非常に為替色の強いワードクラウドになりました。
新アメリカ大統領や日銀総裁の名前もあります。
源氏物語
源氏物語の世界から収集し、17,745行、910,101文字からなるコーパスを作成しました。

古文らしい結果ですが動詞などの意味のない単語が多すぎて源氏物語っぽさを感じません。
ヴォイニッチ手稿
ここまではMeCabでも同じ結果を出せそうな気がするので、現在も未解読のヴォイニッチ手稿でワードクラウドを作ってみました。
トランスクリプトはv101を使用しました。
ちなみにヴォイニッチ手稿は全ページの高解像度スキャンが公開されています。
http://www.bibliotecapleyades.net/ciencia/esp_ciencia_manuscrito07.htm
http://imgur.com/gallery/BVnkL
またヴォイニッチ手稿は分かち書きされていますが、これはフェイクの可能性もありますので全ての空白文字を除去して学習を行いました。
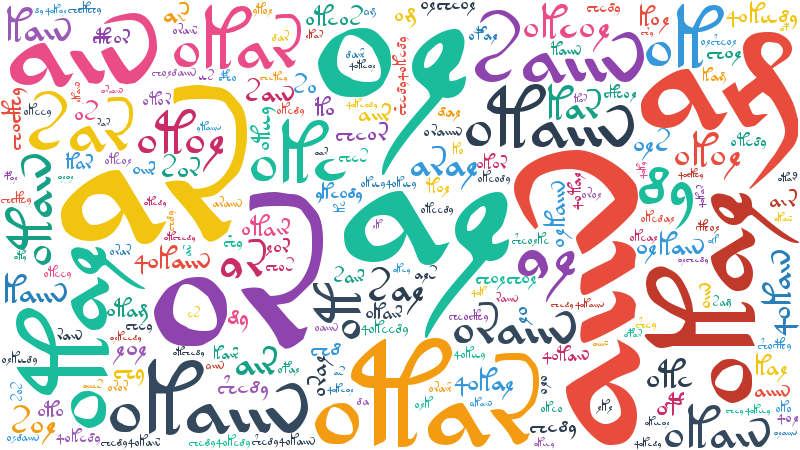
ヴォイニッチ手稿はパターンの繰り返しが非常に多い言語なので、ワードクラウドにも似たような単語が並んでいます。
おわりに
今回使ったコードはGithubにあります。
https://github.com/musyoku/unsupervised-wordcloud
例によってNPYLMの特許の関係でソースを公開できないので、共有ライブラリをPythonから読み込み形になっています。
余談ですが私はヴォイニッチ手稿の解析に興味があるので、今後は教師なし品詞推定などでさらに深く追求していこうと思います。