
WaveNet - A Generative Model for Raw Audio [arXiv:1609.03499]
概要
- WaveNet: A Generative Model for Raw Audio を読んだ
- Chainer 1.12で実装した
はじめに
Google DeepMindが音声生成の新たな手法を開発し発表しましたが、これが従来手法を大きく超える高い品質の音声を生成できると話題になりました。
発表から数日でGitHubには様々な実装が公開されましたが、私もChainerで実装してみました。(→GitHub)
このWaveNetを実装するにあたり、
- 実装の詳細が論文に書いていない
- 1秒の音声を生成するのに90分かかる
- 学習コストが大きい
といった点に注意が必要です。
特に音声生成はリアルタイムで行えるような速度が出ません。
DeepMindの中の人のツイートによると1秒の音声を90分かけて生成したそうですが、音楽CDの音質と同じサンプリング周波数44,100Hzで生成するとそのくらいかかります。
電話並みの8,000Hzに落としても1秒あたり数分~十数分かかります。
また実装に関しても例によって詳細は全く書かれていないため、私の実装が本当に正しいのかどうか分かりません。
音声データの取り扱い
一般的なwavファイル(16bit PCM)は各時刻において-32768~32767の65535通りの値を持ちます。
WaveNetは次の時刻における値をソフトマックス層から出力するのですが、65535個もユニットを作るのは無駄が多いため、μ-lawアルゴリズムによって256段階に圧縮します。
その後one-hotなベクトル(255個の要素が0で1つだけ1の要素を持ったベクトル)に変換しWaveNetへの入力とします。
これは論文に書かれていないため推測ですが、私の実装では各時刻のデータを1ピクセル$\times$1ピクセルの画像にし、チャンネル数を256にしてここをone-hotベクトルとみなすことにしました。
図で表すとこんな感じです。
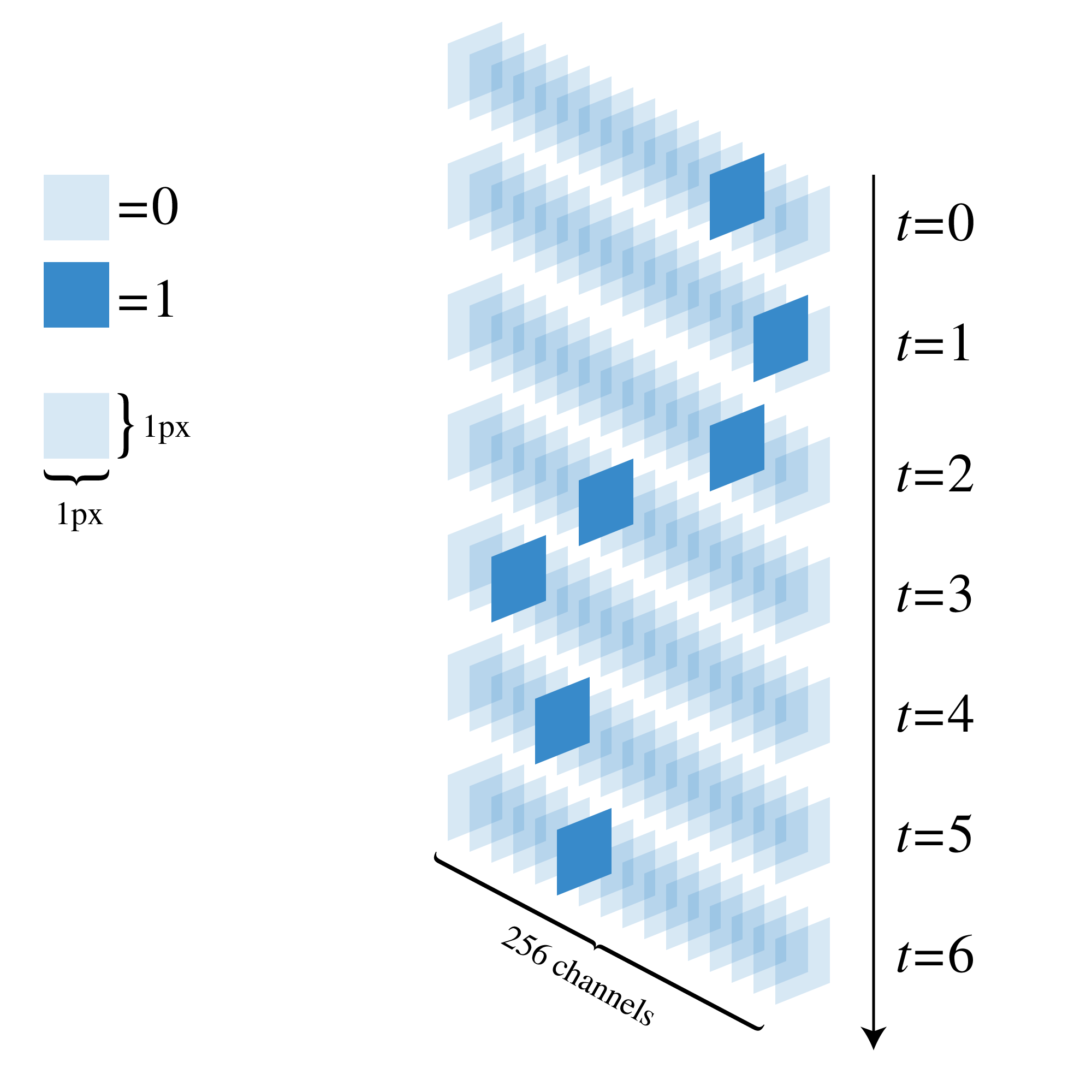
またサンプリング周波数は学習速度とのトレードオフになります。
実験する場合は16,000Hzか8,000Hzに落として行いました。
DeepMindが発表したような品質で学習させると数週間くらいかかると思います。
Dilated Causal Convolution
WaveNetでは過去のある時刻までの範囲の全ての信号を入力として取り、次の時刻の信号を予測します。
言ってみればRNNと同じようなものです。
この「次の信号を予測するために過去のデータをどの程度見るか」という範囲のことを受容野と論文では呼んでいます。
この受容野に対しWaveNetはRNNではなく畳み込みニューラルネットを使って時系列を考慮した特徴量を取り出します。
この時、受容野の広さが100ミリ秒だとすると、音声データのサンプリング周波数が44,100Hzだった場合、受容野には$44100 \times 0.1 = 4410$個もの信号が存在し、これら全てをWaveNetの畳み込み層は同時に見なければなりません。
論文中の図を借りて説明しますが、仮に畳み込みフィルタの幅が2だった場合、4410個の信号を畳み込んでいくと、畳み込み層は4409層必要になります。
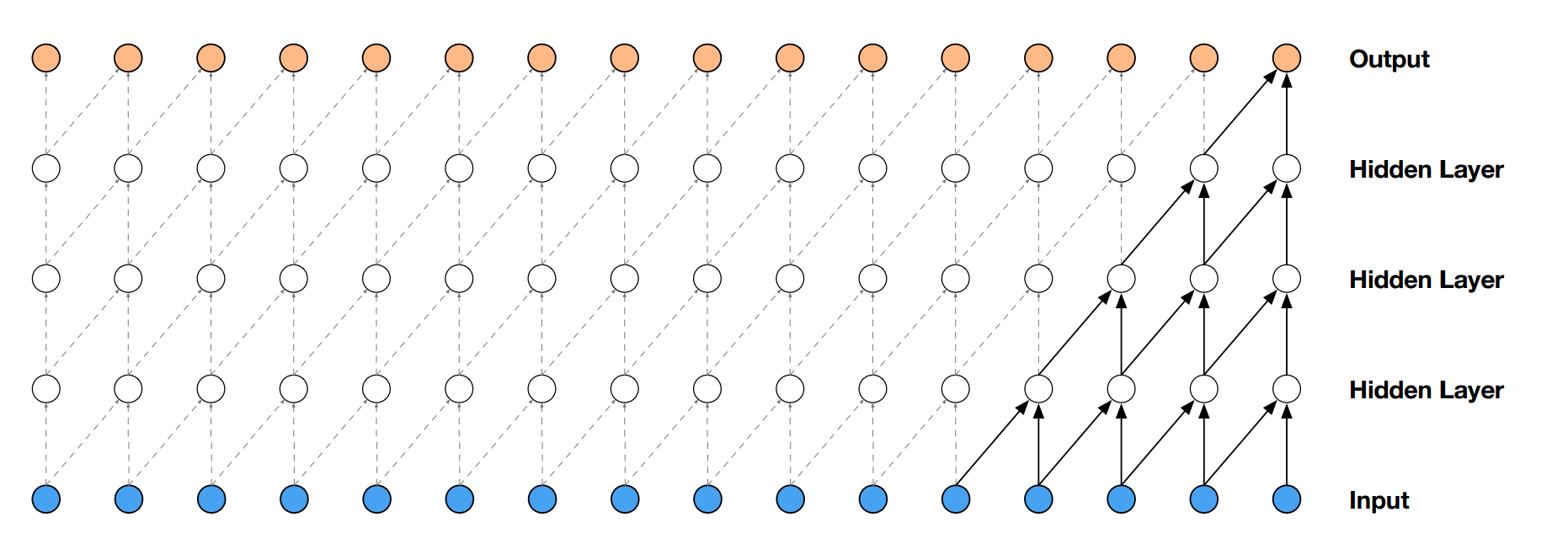
(極端に言うとフィルタサイズが4410なら1層で済みます)
この問題を解決するために使うのがDilated Convolutionです。(atrous convolutionとかconvolution with holesと呼ばれたりします)
すべての層でフィルタサイズは2とします。
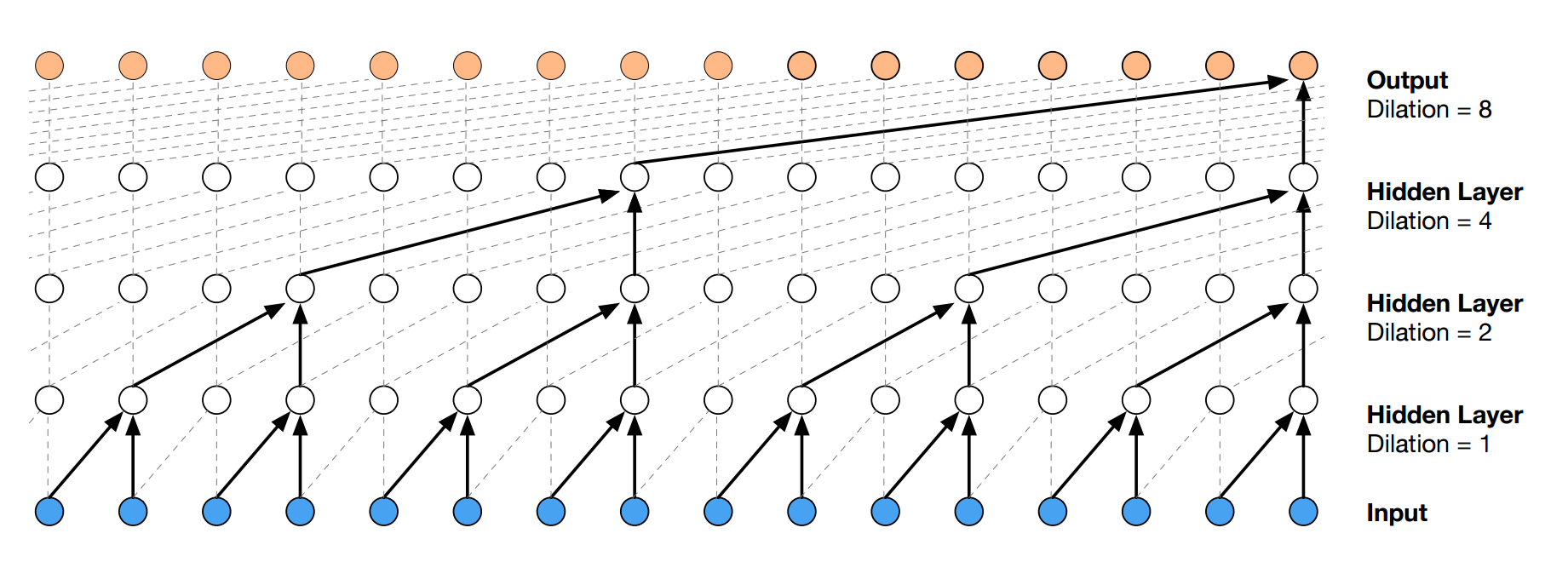
dilationが1なら通常の畳込み、2なら1つ飛ばし、8なら7つ飛ばしで畳み込んでいきます。
(dilationは$filter\_size^{layer\_index}$で計算できます。)
こうすることでたった4層の畳み込み層の受容野が16になります。
$n$層なら受容野の幅は$2^n$になりますので、通常の畳込み層を重ねるよりもはるかに効率よく広い受容野を作ることができます。
(先ほどの4410の幅をたった13層でカバーできてしまいます)
Dilated Convolutionをアニメーションにすると以下のようになります。
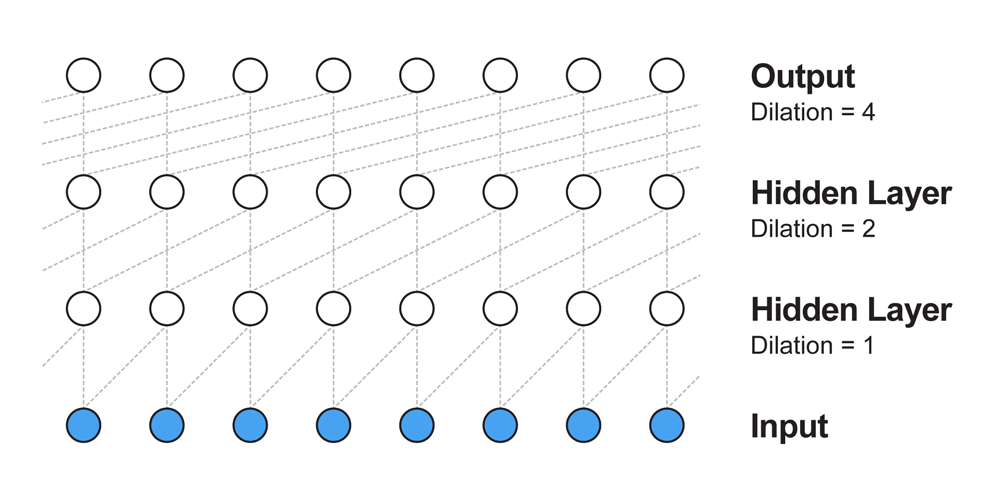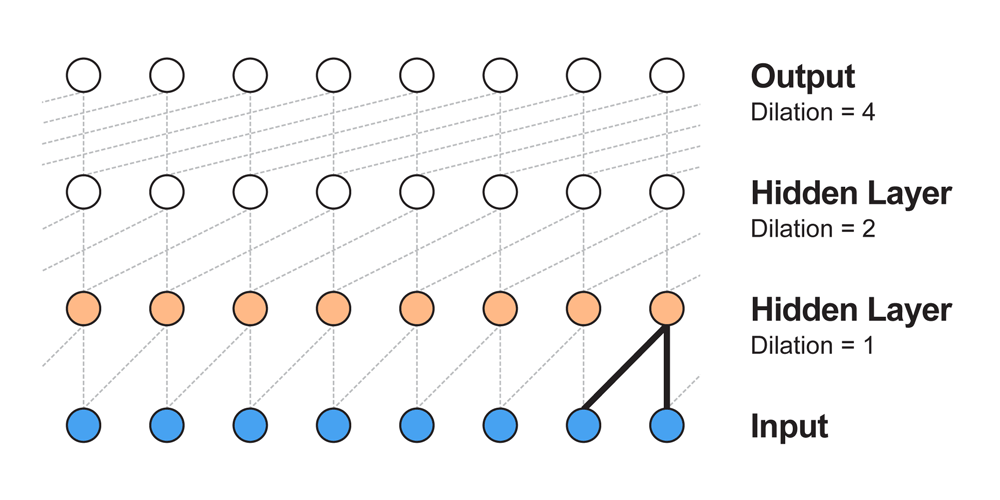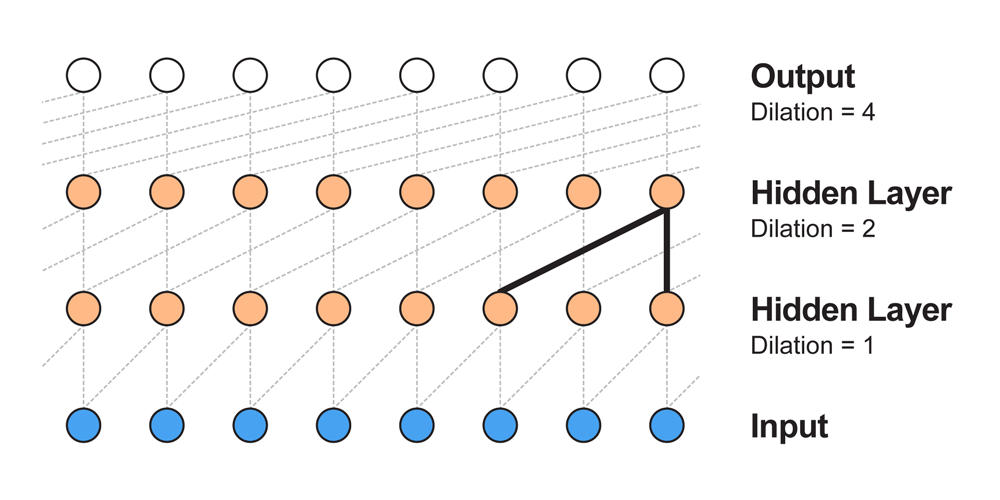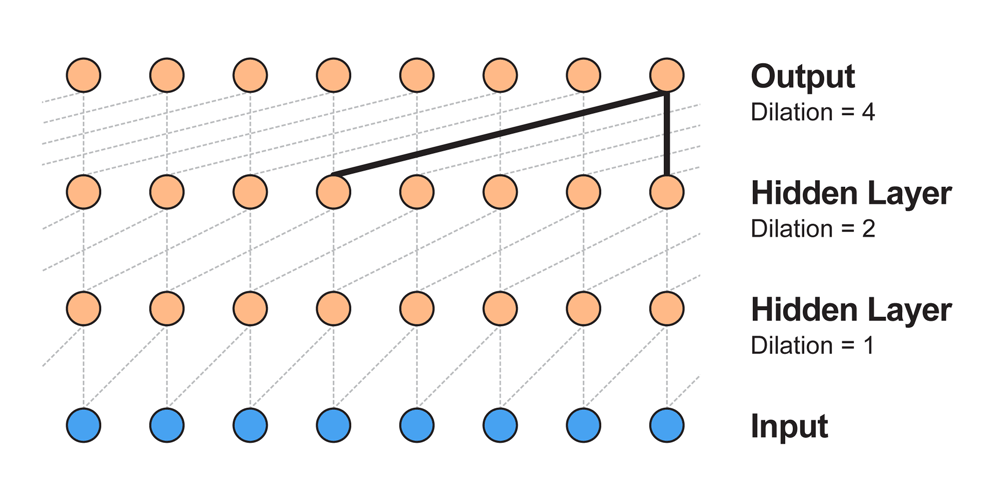
左側の何も写っていない場所はパディングがあります。
このDilated ConvolutionはChainerの次期バージョンで利用できるようになりますが、今回は自作しました。
Residual Block
上記のDilated Convolutionは、例えば最大dilationが4だとするとdilation=1,2,4の3層の畳み込み層になりますが、これを1つの大きな畳み込み層とみなします。
つまり、あたかもフィルタサイズ16の1層の畳み込み層であるかのように考えます。
このみなし畳み込み層を1ブロックとして、何層にも積み重ねて深いネットワークを作ります。
ただ深くするだけでは学習が進まないため、Residual Networkと呼ばれる構造を取り入れます。
ResNet(Residual Network)は画像認識の分野で成功しており、100層~1000層の畳込みニューラルネットの学習を可能にします。
WaveNetでは以下のように畳み込み層を積み重ねていきます。
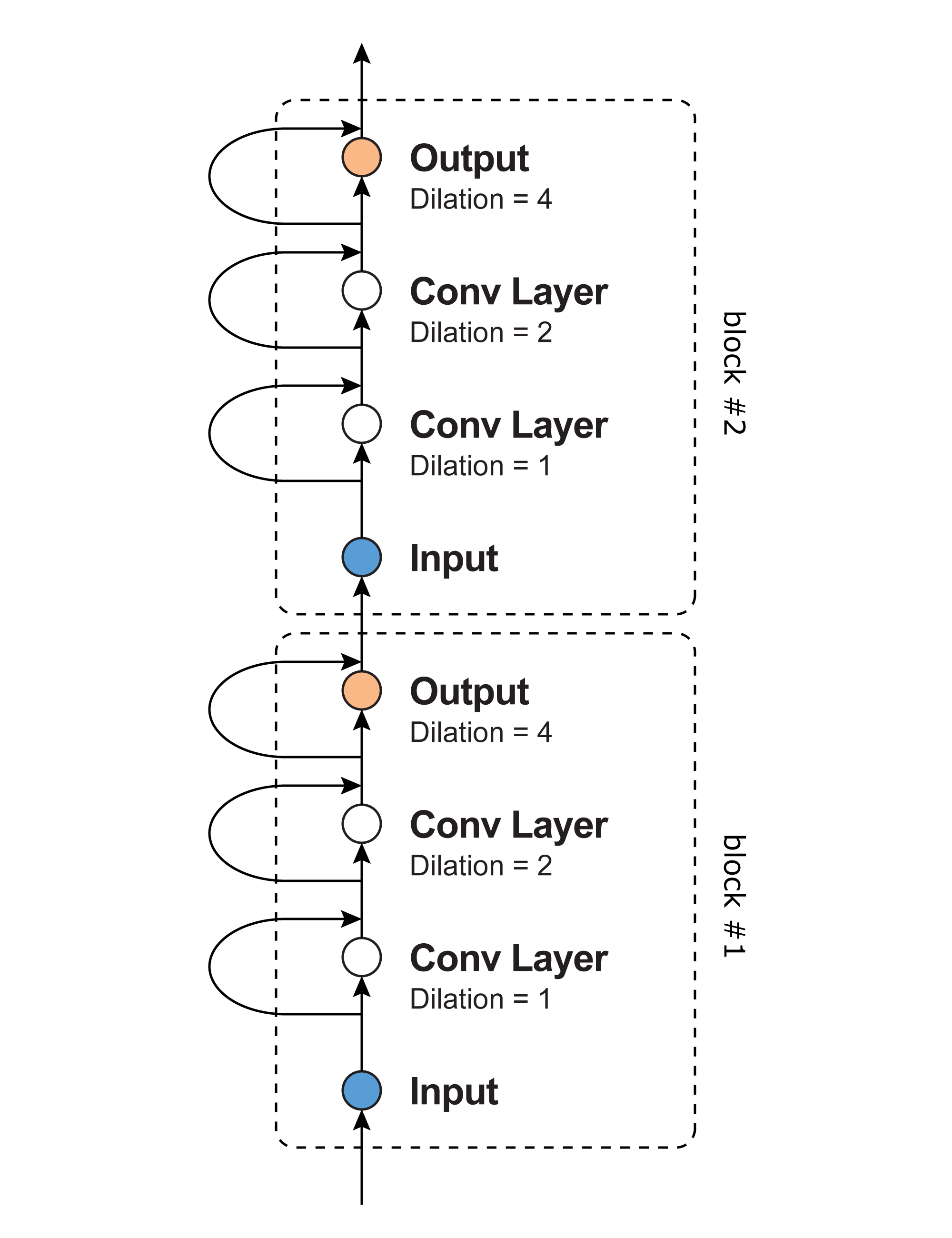
入力が畳み込み層をスキップし出力と合流しているのがResNetの特徴です。
(図では省略していますが畳み込んだあと入力のチャンネル数に合わせるための$1 \times 1$フィルタの畳み込み層が入ります。)
また、ブロックを積み重ねると受容野の幅が大きくなります。
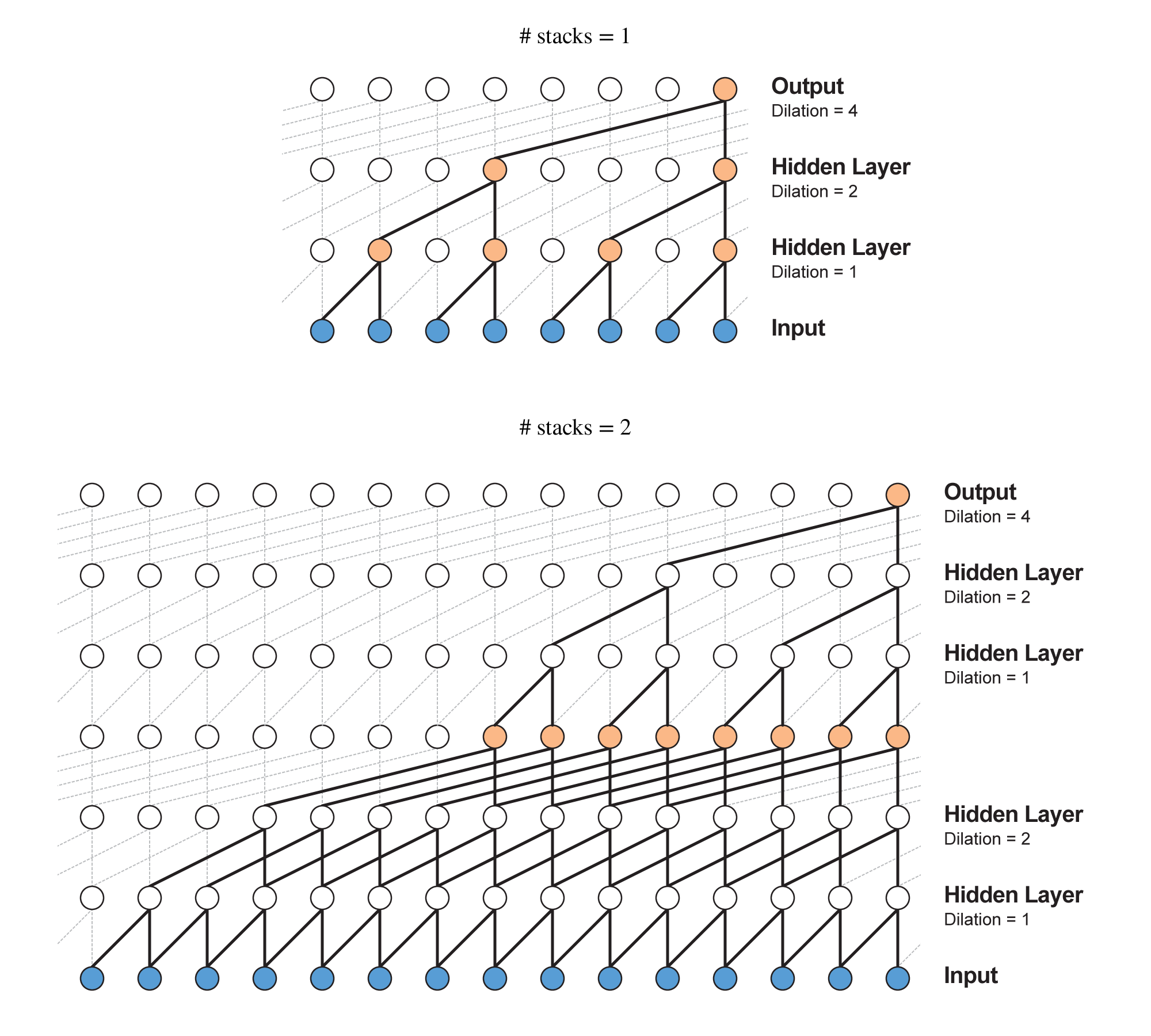
ブロックの受容野の幅を$w_{rf}$とすると$n$ブロック積み重ねた時の受容野の幅は$n \times w_{rf}$になります。(厳密には違いますが)
よって、ブロック内の畳み込み層を増やしてdilationを大きくすると受容野の幅は指数関数的に大きくなり、ブロックを積み重ねると線形に大きくなります。
学習
WaveNetはResidual Networkを使うため入力層、隠れ層、出力層で扱うデータの各次元の要素数は全て同じになります。
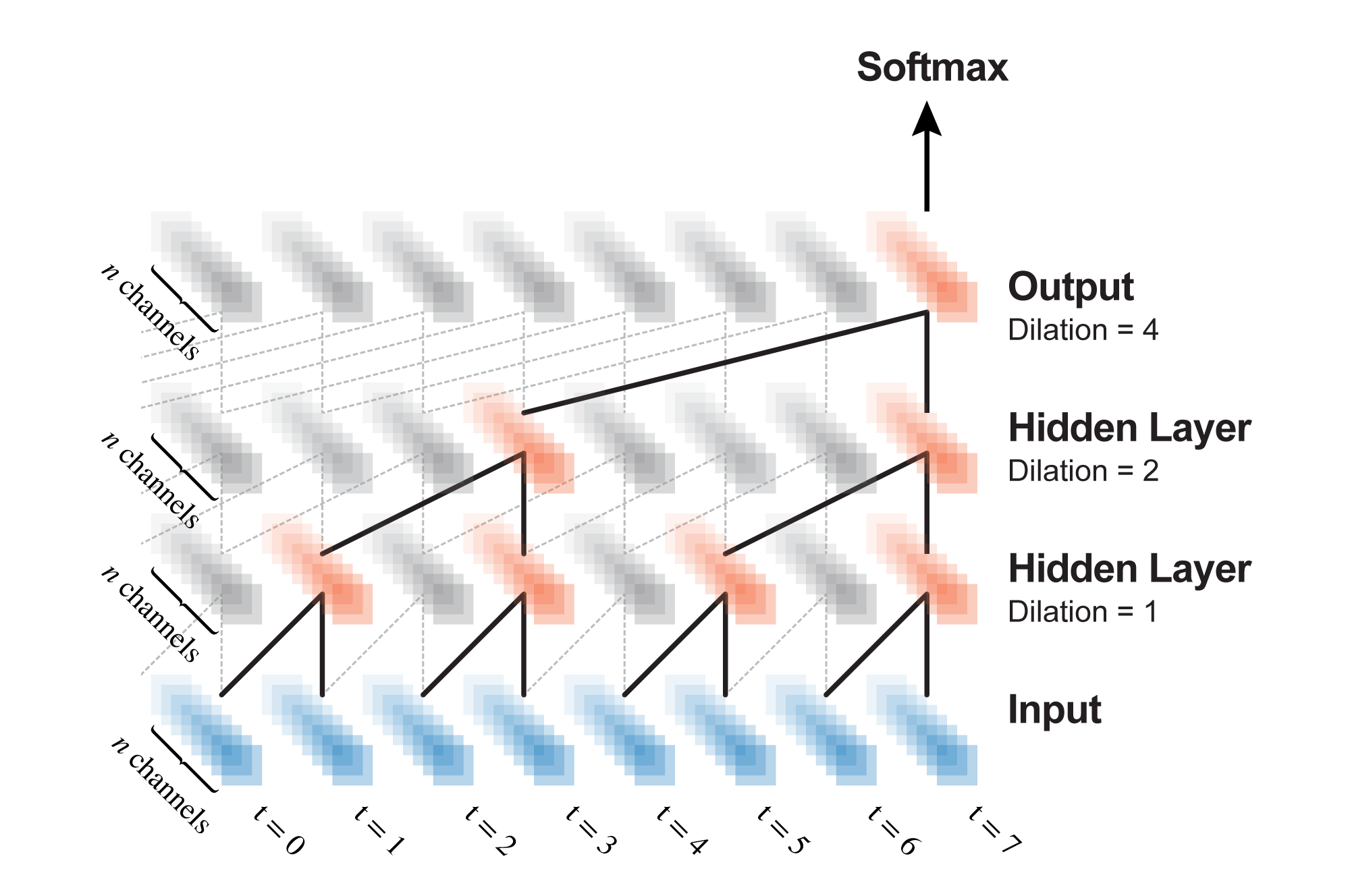
例えば受容野の幅が8ステップだった場合出力層からも8ステップぶんのデータが出てきますが、一番右端以外は不要ですので無視して一番右だけsoftmaxに入れ次の時刻の音声信号を予測します。
(ちなみに出力の一番右の要素以外の要素は入力をゼロパディングして畳み込んで作ったものです)
予測
次の時刻の信号を予測するにはRNNと同様に過去の時刻の信号を入力します。
このときWaveNetの受容野の幅をあらかじめ計算しておき、入力する過去の信号の個数は受容野の幅と同じになるようにします。
例えば受容野の幅が10の場合、$t=0,1,2,3,4,5,6,7,8,9$の信号を入力し、$t=10$の信号の確率を出力させます。
RNNと違う点は過去のデータを固定幅で扱うところです。
WaveNetの出力は256個のユニットになっており、それぞれのユニットが、次の時刻の信号がその(圧縮後の)値になる確率を表しています。
次の時刻の信号をサンプリングし0~255のいずれかの値に確定させます。
入力の圧縮に使ったμ-lawアルゴリズムは逆関数があるので、サンプリングした値を-1~1に正規化し逆関数を通してから(16bit PCMなら)32767をかけてwavデータにします。
予測の高速化
早くもFast WaveNetが公開されていますが、予測する際は過去の信号を畳み込んだ結果を再利用することができるため、予測を高速に行うことができます。
畳み込み層のバイアスについて
Residualなネットワークでは畳み込み層にバイアスを用いないそうなのですが、WaveNetの場合ソフトマックス部にはバイアスを用いないと学習が停滞してしまいます。
Residualブロックの畳み込み層に関してはバイアスありなしどちらも学習には影響を与えないような感じがします。
実験
5秒ほどのBGMを学習させて生成させてみました。
今回は生成というよりは丸暗記ですが、WaveNetはどのような音も学習することができます。
またフィルタサイズは3にして学習させました。
終わりに
実装を間違えているような気がしてならないのですが、短い音源を学習させてテストをしてみたところ一応生成はちゃんとできています。
また学習用の音声はサンプリング周波数を8000以下に落とさないと学習に時間がかかるため、DeepMindが発表したような人間の声と聞き間違うレベルの品質で音声生成をするには私の環境では難しいと思います。
というよりも個人レベルの計算環境でやるものではないと思います。