
ChainerのChainをもっと楽に書く
概要
- Chainerのモデル定義クラスを新たに作った
はじめに
ChainerのChainをもう少し楽に書くの続きです。
昔書いたAdversarial AutoEncoderのコードを書きなおしていたんですが、モデル定義の部分を簡潔に書くのが難しかったので新たにモデル定義クラスを作りました。
chainer.Chainのモデル定義はもともと以下のように書きます。
class Model(chainer.Chain):
def __init__(self, n_in, n_hidden, n_out):
super(Model, self).__init__()
with self.init_scope():
self.layer1 = L.Linear(n_in, n_hidden)
self.layer2 = L.Linear(n_hidden, n_hidden)
self.layer3 = L.Linear(n_hidden, n_out)
def __call__(self, x):
h1 = F.relu(self.layer1(x))
h2 = F.relu(self.layer2(h1))
return self.layer3(h2)
Chainer v2からはwith self.init_scope()内でchainer.Linkを追加する必要があります。
単純なネットワークならこの書き方で問題ありませんが、最近のDeep Learningは回路設計の領域に来ており、複雑大規模なネットワークを上のやり方で定義すると順伝播の計算で苦労します。
今回作ったnn.Moduleクラスでは、PyTorchやKerasなどの一般的なsequentialクラスと同じ形で書けます。
module = nn.Module(
nn.Linear(784, 1000),
nn.ReLU(),
nn.Linear(1000, 1000),
nn.ReLU(),
nn.Linear(1000, 2),
nn.ReLU(),
)
nn.Moduleはchainer.Chainを継承しているため、使い方は同じです。
出力を計算するには__call__を呼びます。
y = module(x)
ここまでは前回と同じですが、これだけでは不十分なケースが多くあったため改良しました。
まずnn.Moduleのオブジェクトに直接chainer.Linkを追加できるようになりました。
module = nn.Module(
nn.Linear(1000, 1000),
nn.ReLU(),
nn.Linear(1000, 1000),
nn.ReLU(),
nn.Linear(1000, 2),
nn.ReLU(),
)
module.additional_layer = nn.Linear(1000, 1000)
見た目上は通常のオブジェクトへの要素の追加と変わりませんが、内部的には以下のような動作になっており、適切にchainer.Chainに追加されます。
with module.init_scope():
module.additional_layer = L.Linear(1000, 1000)
これのメリットは下層のみ共有するようなネットワークを書ける点にあります。
たとえば入力からガウス分布の平均と分散を得て出力を計算する場合は以下のように書けます。
module = nn.Module(
nn.Linear(1000, 1000),
nn.ReLU(),
nn.Linear(1000, 1000),
nn.ReLU(),
)
module.mean = nn.Linear(1000, 2)
module.ln_var = nn.Linear(1000, 2)
internal = module(x)
mean = module.mean(internal)
ln_var = module.ln_var(internal)
z = chainer.functions.gaussian(mean, ln_var)
さらにnn.Moduleにnn.Moduleを追加することもできます。
module = nn.Module(
nn.Linear(1000, 1000),
nn.ReLU(),
nn.Linear(1000, 1000),
nn.ReLU(),
)
module.mean = nn.Module(
nn.Linear(1000, 1000),
nn.ReLU(),
nn.Linear(1000, 2),
)
module.ln_var = nn.Module(
nn.Linear(1000, 1000),
nn.ReLU(),
nn.Linear(1000, 2),
)
internal = module(x)
mean = module.mean(internal)
ln_var = module.ln_var(internal)
z = chainer.functions.gaussian(mean, ln_var)
上のコードは内部的には以下のような動作をします。
with module.init_scope():
module.link_1 = L.Linear(1000, 1000)
module.link_2 = L.Linear(1000, 1000)
with module.mean.init_scope():
module.mean.link_1 = L.Linear(1000, 1000)
module.mean.link_2 = L.Linear(1000, 2)
with module.ln_var.init_scope():
module.ln_var.link_1 = L.Linear(1000, 1000)
module.ln_var.link_2 = L.Linear(1000, 2)
with module.init_scope():
module.mean_link_1 = module.mean.link_1
module.mean_link_2 = module.mean.link_2
module.ln_var_link_1 = module.ln_var.link_1
module.ln_var_link_2 = module.ln_var.link_2
ポイントは子にchainer.Linkを追加すると親にも追加される点です。
この動作のメリットは以下のようにnn.Moduleを継承したクラスを考えると分かりやすいです。
class Model(nn.Module):
def __init__(self):
super().__init__()
self.encoder = nn.Module(
...
)
self.decoder = nn.Module(
...
)
self.generator = nn.Module(
...
)
self.discriminator = nn.Module(
...
)
model = Model()
model、model.encoder、model.decoder、model.generator、model.discriminatorがそれぞれchainer.Chainになっています。
この時、親であるmodelは、子のnn.Moduleが持っている全てのchainer.Linkを持っているため、モデルのパラメータを保存する際は親を保存するだけで全ての子のパラメータも保存されます。
chainer.serializers.save_hdf5("model.hdf5", model)
Optimizerも同様です。
optimizer = chainer.optimizers.SGD()
optimizer.setup(model)
もちろん個別に行うことも可能です。
optimizer_encoder = chainer.optimizers.SGD()
optimizer_encoder.setup(model.encoder)
optimizer_decoder = chainer.optimizers.SGD()
optimizer_decoder.setup(model.decoder)
optimizer_discriminator = chainer.optimizers.SGD()
optimizer_discriminator.setup(model.discriminator)
optimizer_generator = chainer.optimizers.SGD()
optimizer_generator.setup(model.generator)
この機能は階層が深くなっても動作するため、以下のような極端な例でもmodelは全てのchainer.Linkを持っています。
class Model(nn.Module):
def __init__(self):
super().__init__()
self.extremely = nn.Module(
...
)
self.extremely.deep = nn.Module(
...
)
self.extremely.deep.module = nn.Module(
...
)
model = Model()
パラメータの初期化も親の__init__内で行えば、全ての子のパラメータを初期化できます。
class Model(nn.Module):
def __init__(self):
super().__init__()
...
for param in self.params():
if param.name == "W":
param.data[...] = np.random.normal(0, 0.01, param.data.shape)
ResNet
前回に引き続きresidualな接続も可能です。
model = nn.Module(
nn.Residual(
nn.Convolution2D(None, 64, 3),
nn.BatchNormalization(),
nn.ReLU(),
nn.Convolution2D(None, 64, 3),
nn.BatchNormalization(),
),
nn.ReLU(),
nn.Residual(
nn.Convolution2D(None, 64, 3),
nn.BatchNormalization(),
nn.ReLU(),
nn.Convolution2D(None, 64, 3),
nn.BatchNormalization(),
),
nn.ReLU(),
nn.Residual(
nn.Convolution2D(None, 64, 3),
nn.BatchNormalization(),
nn.ReLU(),
nn.Convolution2D(None, 64, 3),
nn.BatchNormalization(),
),
nn.ReLU(),
)
y = model(x)
nn.Residualでは、ユニット出力をユニット入力に足しあわせて最終出力とします。
y = layer(x)
if isinstance(layer, Residual) and x.shape == y.shape:
y += x
shapeが違う場合は足さないようになっているため、徐々にチャネル数を増やしていくような場合でも気にせず使えます。
ブロック
nn.Moduleのaddメソッドでレイヤーを追加した場合、addしたレイヤー集合を1ブロックとみなします。
module = nn.Module()
module.add(
nn.BatchNormalization(1000),
nn.Linear(1000, 1000),
nn.ReLU(),
nn.Dropout(),
)
module.add(
nn.BatchNormalization(1000),
nn.Linear(1000, 1000),
nn.ReLU(),
nn.Dropout(),
)
module.add(
nn.BatchNormalization(1000),
nn.Linear(1000, 1000),
nn.ReLU(),
nn.Dropout(),
)
ブロックの中身はblocksを呼ぶことで取得できます。
use_batchnorm = True
use_dropout = True
x = np.random.normal(0, 1, (100, 1000)).astype(np.float32)
for block in module.blocks():
batchnorm, linear, f, dropout = block
if use_batchnorm:
x = batchnorm(x)
x = linear(x)
x = f(x)
if use_dropout:
x = dropout(x)
デバッグがやりやすいです。
応用例
Adversarial AutoEncoder(以下AAE)を例に使い方を説明します。
AAEでは様々なモデルでいろいろなタスクを解いているのですが、その中でも一番ネットワーク構造が複雑なものが以下のようになっています。
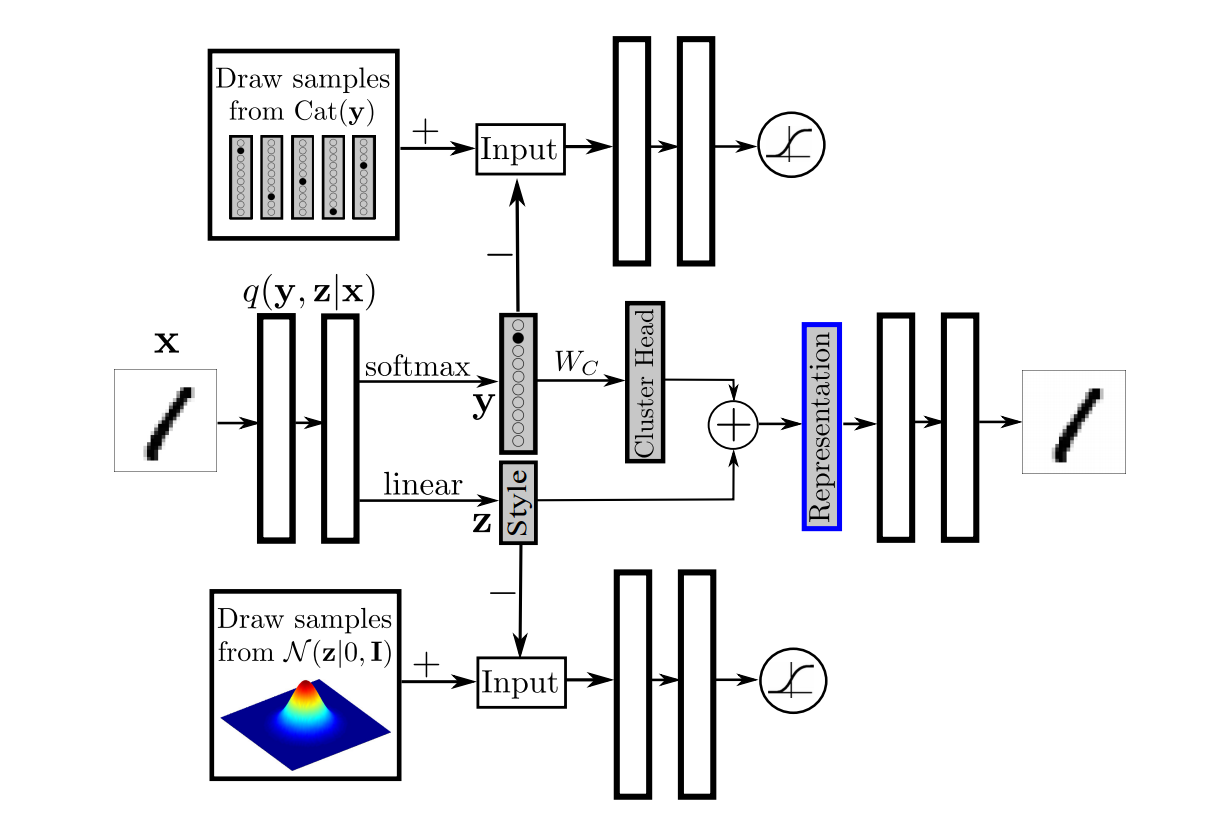
(論文より引用)
このモデルは
- 入力$\boldsymbol x$をスタイル$\boldsymbol z$とカテゴリ$\boldsymbol y$に変換するencoder(兼generator)
- スタイル$\boldsymbol z$が本物かどうかを見分けるdiscriminator_z
- カテゴリ$\boldsymbol y$が本物かどうかを見分けるdiscriminator_y
- $\boldsymbol y$をCluster Headに変換する線形レイヤーcluster_head
- $\boldsymbol {representation}$から$\boldsymbol x$を再構成するdecoder
の5つの要素から成り立っています。
これをChainerで実装する場合に、ネットワーク構造を自在に変化させて実験ができるような柔軟なモデル定義のコードを素のchainer.Chainで書くのは苦労します。
これを今回作ったchainer.nnで書くと、それぞれ以下のようになります。
Decoder
decoder = nn.Module(
nn.Linear(ndim_z, ndim_h),
nn.ReLU(),
nn.Linear(ndim_h, ndim_h),
nn.ReLU(),
nn.Linear(ndim_h, ndim_x),
nn.Tanh(),
)
Encoder
encoder = nn.Module(
nn.Linear(ndim_x, ndim_h),
nn.ReLU(),
nn.Linear(ndim_h, ndim_h),
nn.ReLU(),
)
encoder.head_y = nn.Linear(ndim_h, ndim_y)
encoder.head_z = nn.Linear(ndim_h, ndim_z)
Discriminator($\boldsymbol z$)
discriminator_z = nn.Module(
nn.GaussianNoise(std=0.3),
nn.Linear(ndim_z, ndim_h),
nn.ReLU(),
nn.Linear(ndim_h, ndim_h),
nn.ReLU(),
nn.Linear(ndim_h, 2),
)
Discriminator($\boldsymbol y$)
self.discriminator_y = nn.Module(
nn.GaussianNoise(std=0.3),
nn.Linear(ndim_y, ndim_h),
nn.ReLU(),
nn.Linear(ndim_h, ndim_h),
nn.ReLU(),
nn.Linear(ndim_h, 2),
)
Cluster Head
cluster_head = nn.Linear(ndim_y, ndim_z, nobias=True)
これらをもとにクラスを作ります。
class Model(nn.Module):
def __init__(self, ndim_x=28*28, ndim_y=10, ndim_z=2, ndim_h=1000, cluster_head_distance_threshold=1):
super(Model, self).__init__()
self.ndim_x = ndim_x
self.ndim_y = ndim_y
self.ndim_z = ndim_z
self.ndim_h = ndim_h
self.cluster_head_distance_threshold = cluster_head_distance_threshold
self.decoder = nn.Module(
nn.Linear(ndim_z, ndim_h),
nn.ReLU(),
nn.Linear(ndim_h, ndim_h),
nn.ReLU(),
nn.Linear(ndim_h, ndim_x),
nn.Tanh(),
)
self.encoder = nn.Module(
nn.Linear(ndim_x, ndim_h),
nn.ReLU(),
nn.Linear(ndim_h, ndim_h),
nn.ReLU(),
)
self.encoder.head_y = nn.Linear(ndim_h, ndim_y)
self.encoder.head_z = nn.Linear(ndim_h, ndim_z)
self.discriminator_z = nn.Module(
nn.GaussianNoise(std=0.3),
nn.Linear(ndim_z, ndim_h),
nn.ReLU(),
nn.Linear(ndim_h, ndim_h),
nn.ReLU(),
nn.Linear(ndim_h, 2),
)
self.discriminator_y = nn.Module(
nn.GaussianNoise(std=0.3),
nn.Linear(ndim_y, ndim_h),
nn.ReLU(),
nn.Linear(ndim_h, ndim_h),
nn.ReLU(),
nn.Linear(ndim_h, 2),
)
self.cluster_head = nn.Linear(ndim_y, ndim_z, nobias=True)
for param in self.params():
if param.name == "W":
param.data[...] = np.random.normal(0, 0.01, param.data.shape)
for param in self.cluster_head.params():
if param.name == "W":
param.data[...] = np.random.normal(0, 1, param.data.shape)
def encode_x_yz(self, x, apply_softmax_y=True):
internal = self.encoder(x)
y = self.encoder.head_y(internal)
z = self.encoder.head_z(internal)
if apply_softmax_y:
y = functions.softmax(y)
return y, z
def encode_yz_representation(self, y, z):
cluster_head = self.cluster_head(y)
return cluster_head + z
def decode_representation_x(self, representation):
return self.decoder(representation)
def discriminate_z(self, z, apply_softmax=False):
logit = self.discriminator_z(z)
if apply_softmax:
return functions.softmax(logit)
return logit
def discriminate_y(self, y, apply_softmax=False):
logit = self.discriminator_y(y)
if apply_softmax:
return functions.softmax(logit)
return logit
学習部分などはmusyoku/chainer-nnのexampleにあります。
おわりに
今のところ満足しています。
Chainerの内部仕様にはあまり詳しくないので実装が間違っているかもしれません。