
GAN・VAT・ADGM・AAEでMNISTのワンショット学習
概要
- 様々なモデルでMNISTの半教師あり学習(10ラベル)を行った
はじめに
今までに作ってきた半教師あり学習の手法を用いてMNISTのワンショット学習対決を行ないました。
用いるモデルは以下の4つです。
- GAN (Generative Adversarial Network)
- 通常の多クラス分類器をDiscriminatorとして使う手法を用いる
- MNIST 100ラベルのSOTA(エラー0.93%)
- Improved Techniques for Training GANs
- 実装
- VAT (Virtual Adversarial Training)
- データ$x$の予測分布$p(y \mid x)$と、ノイズ$r$を加えた$\bar{x} = x + r$の予測分布$p(y \mid \bar{x})$が滑らかになるように学習
- 最も予測分布を狂わすノイズ$r_{adv}$を誤差逆伝播で求められる
- モデルというよりは学習法
- Distributional Smoothing with Virtual Adversarial Training
- 実装
- ADGM (Auxiliary Deep Generative Models)
- VAEに補助変数を導入したモデル
- 他にSDGM(Skip Deep Generative Model)も提案している
- MNIST 100ラベルの元SOTA(エラー0.96%)
- Auxiliary Deep Generative Models
- 実装
- AAE (Adversarial AutoEncoder)
- オートエンコーダの隠れ変数をGANで正則化
- Adversarial Autoencoders
- 実装
今回の実験で用いたプログラム一式です。
https://github.com/musyoku/mnist-oneshot
実験条件
MNISTの学習用データは60,000枚ありますので、10,000枚をバリデーション用として学習には用いません。
残りの50,000枚の中から何枚かにだけ正解ラベルを与えます。
これ以降のグラフは全てバリデーションデータに対する分類精度を表します。
またシードは数字が同じであれば全モデルで同じデータに対してラベルを与えています。
さらに得られた分類精度がどの程度良いかを評価するためにベースライン精度も求めます。
これは各モデルの学習ルーチンにおいて、ラベルなしデータを用いた部分を削除した状態で学習を行って求めました。
10ラベル
各数字につき1サンプルにのみ正解ラベルを与えるもので、ワンショット学習と言われています。
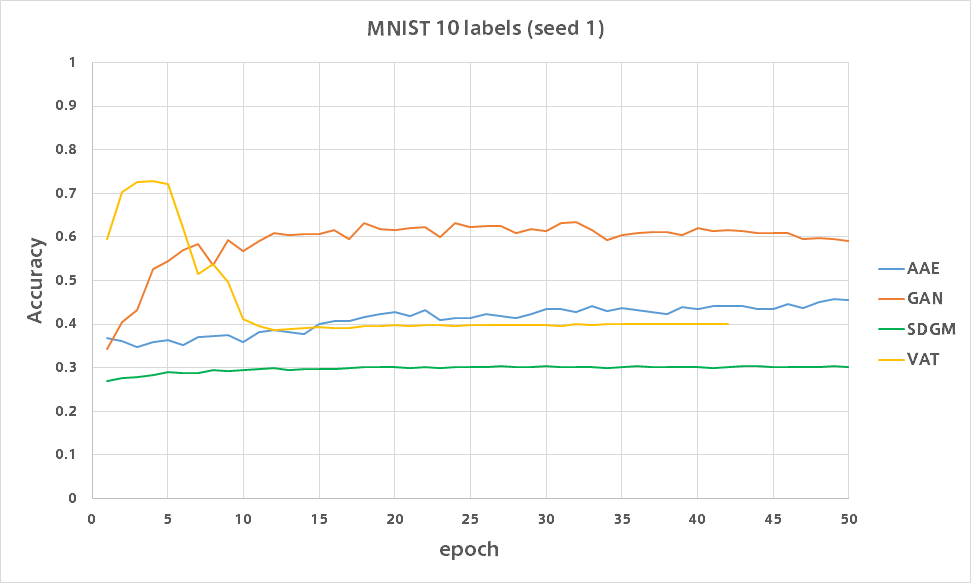
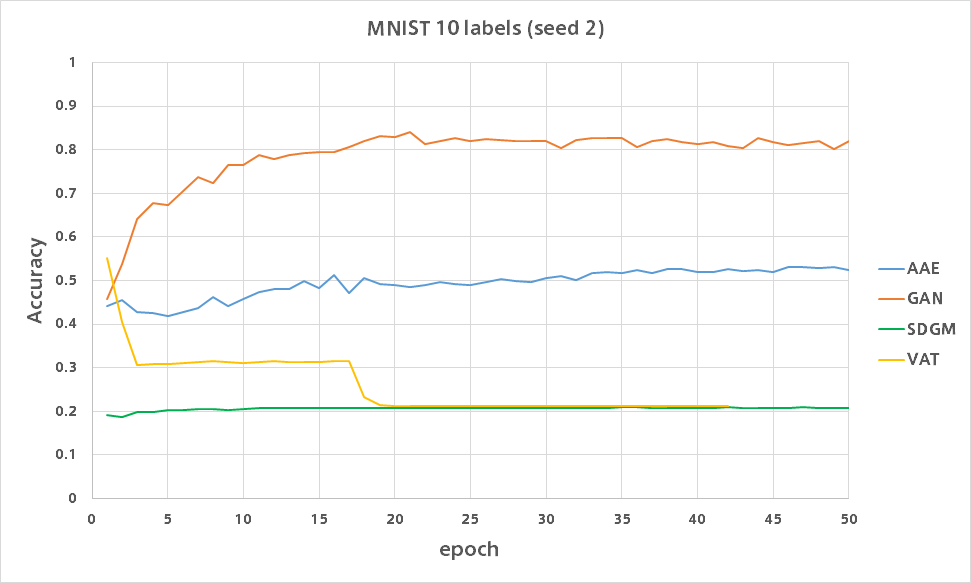
GAN
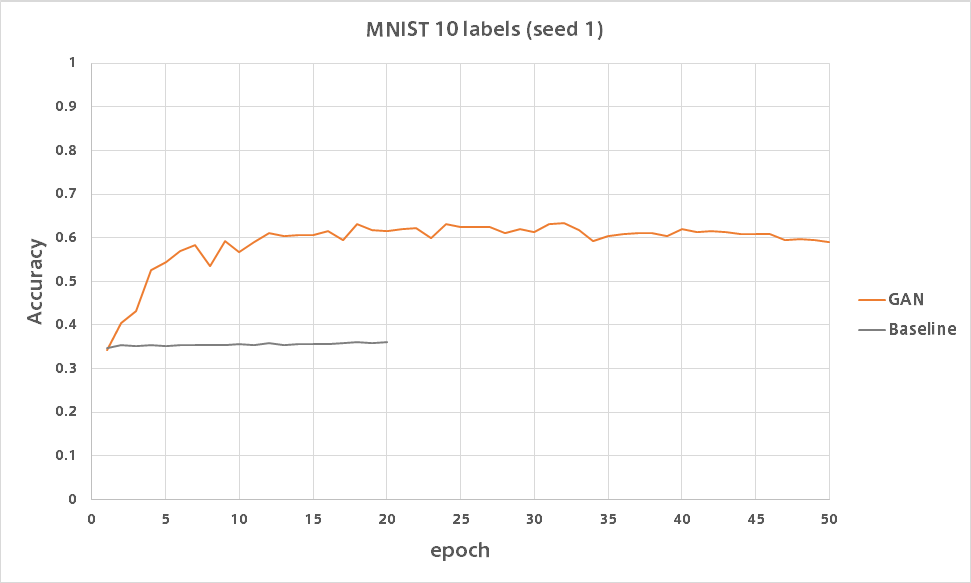
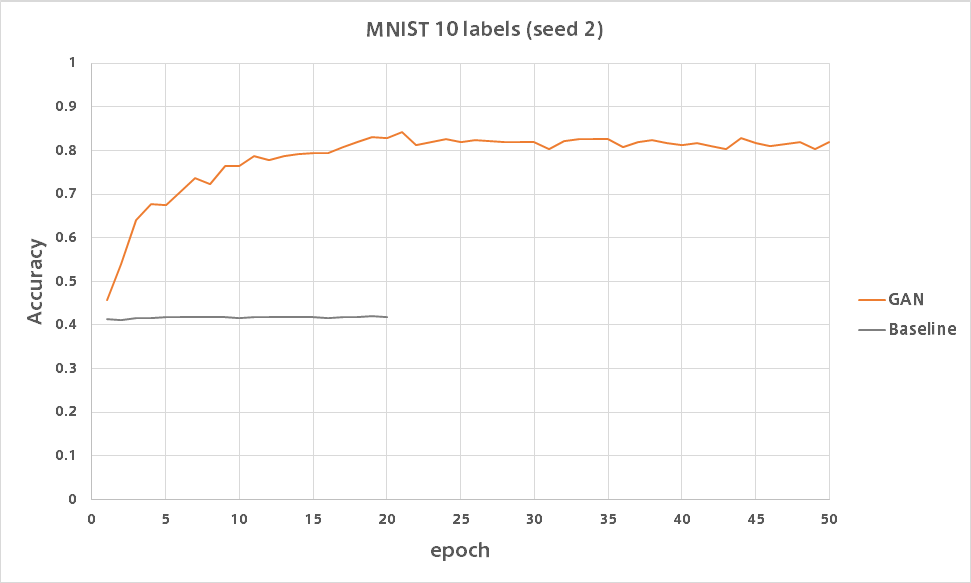
GANはたった10ラベルながらシードによってはバリデーション精度80%を超えました。
VAT
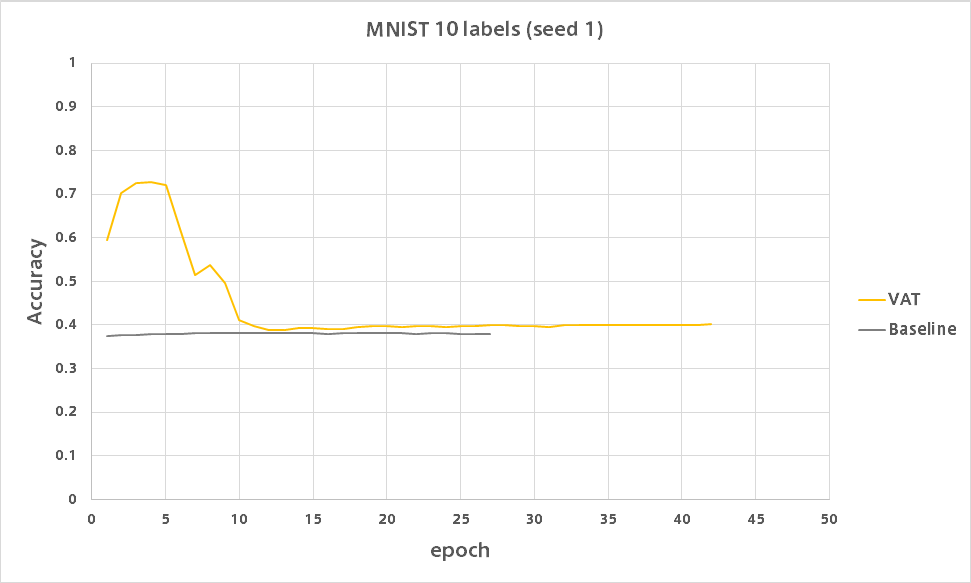
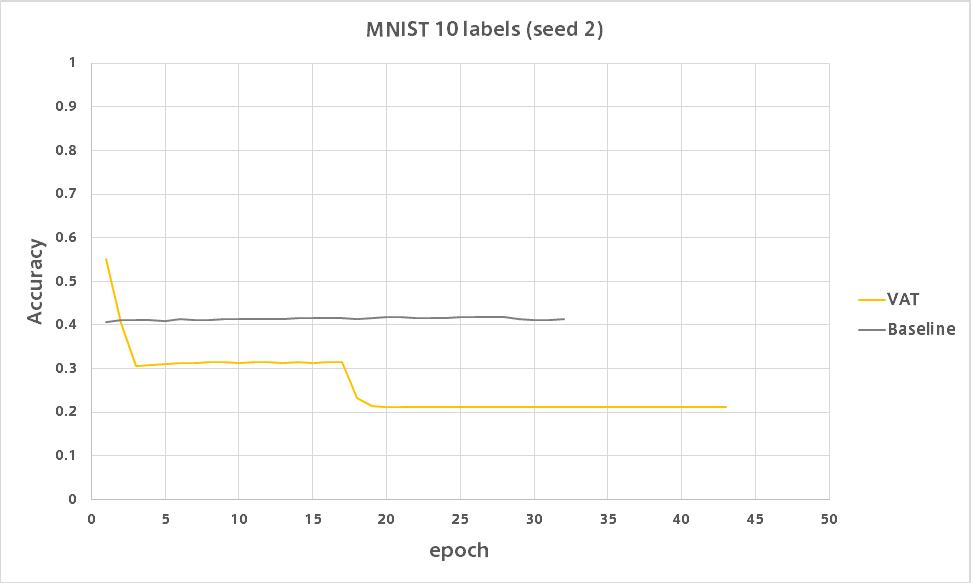
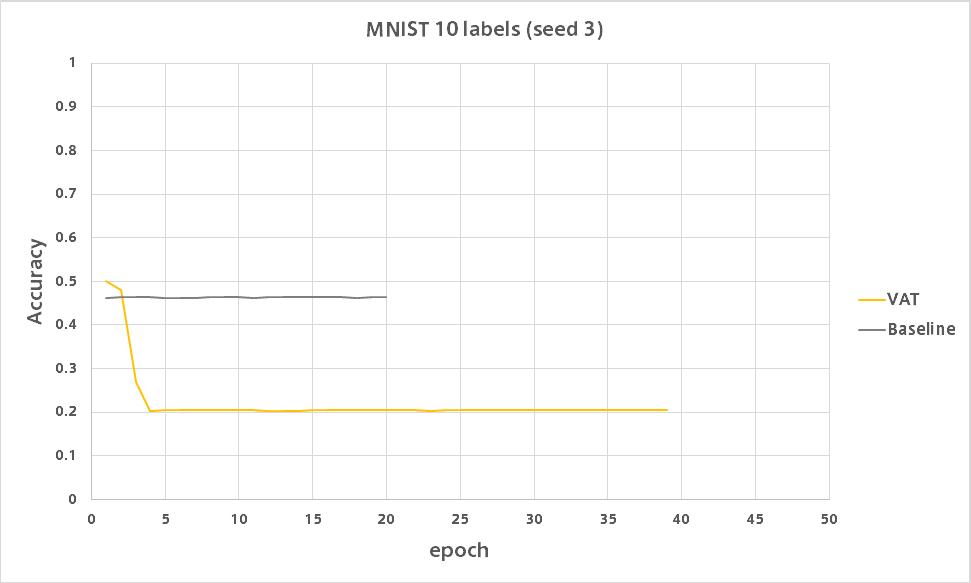
VATは何があったのか低い精度で安定しました。
SDGM
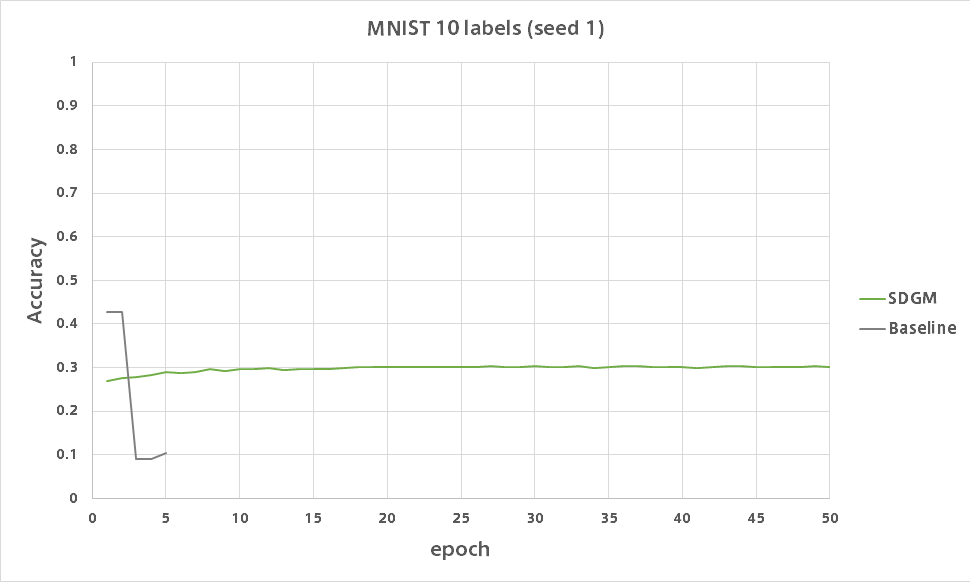
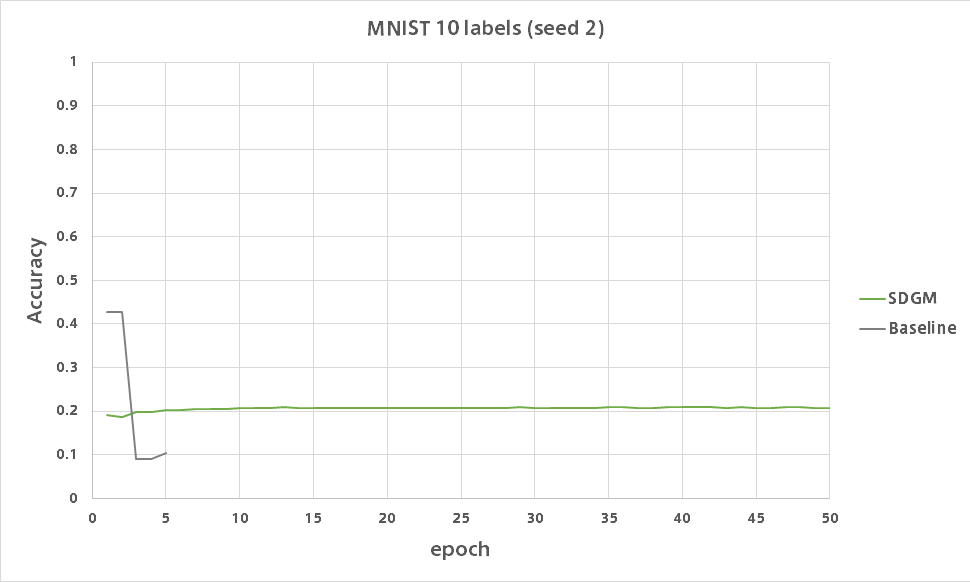
AAE
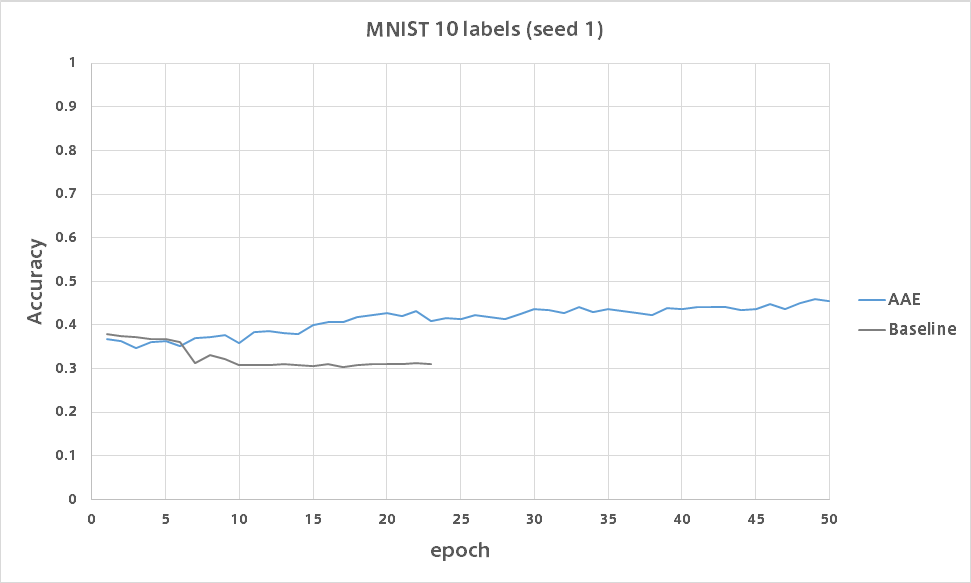
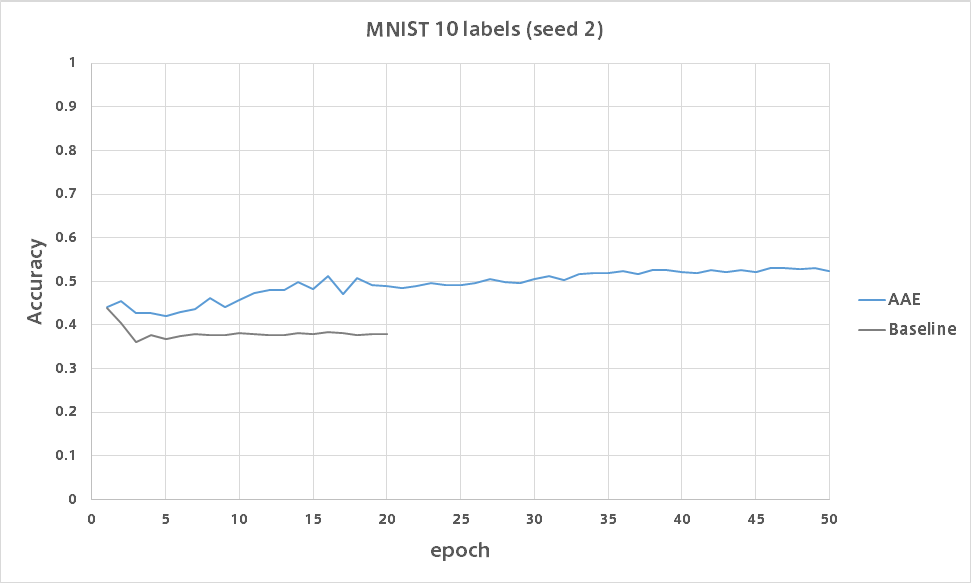
比較
20ラベル
各数字につき2枚にのみ正解ラベルを与えます。
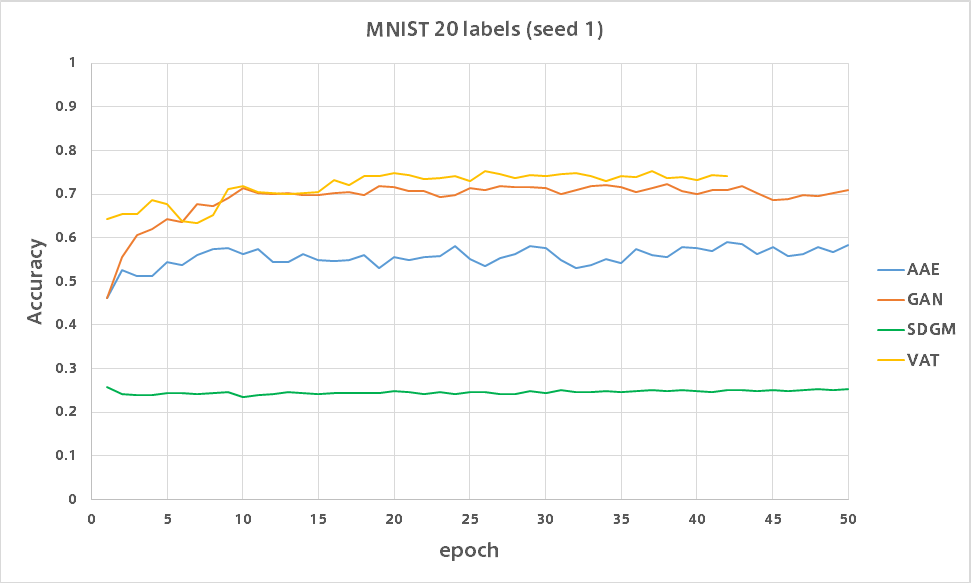
GAN
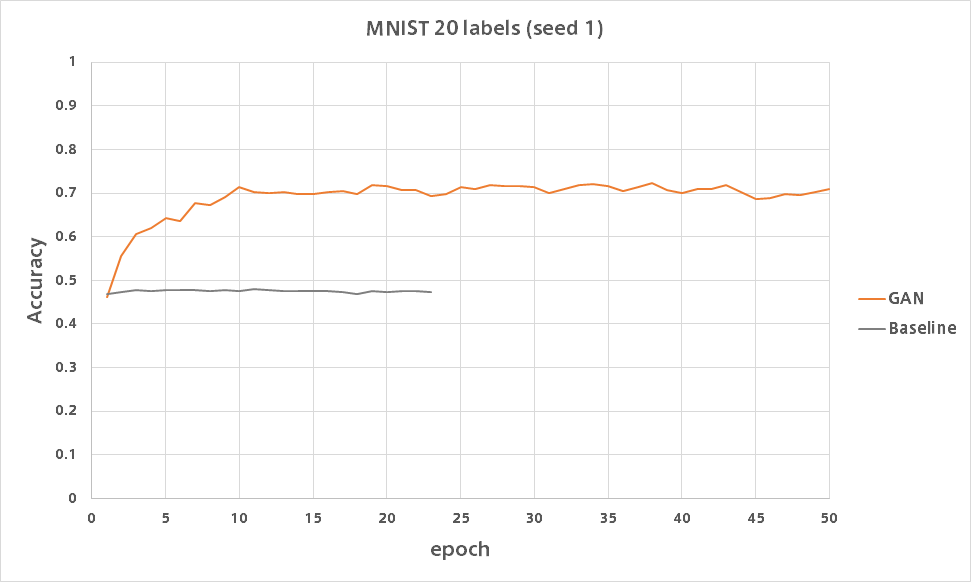
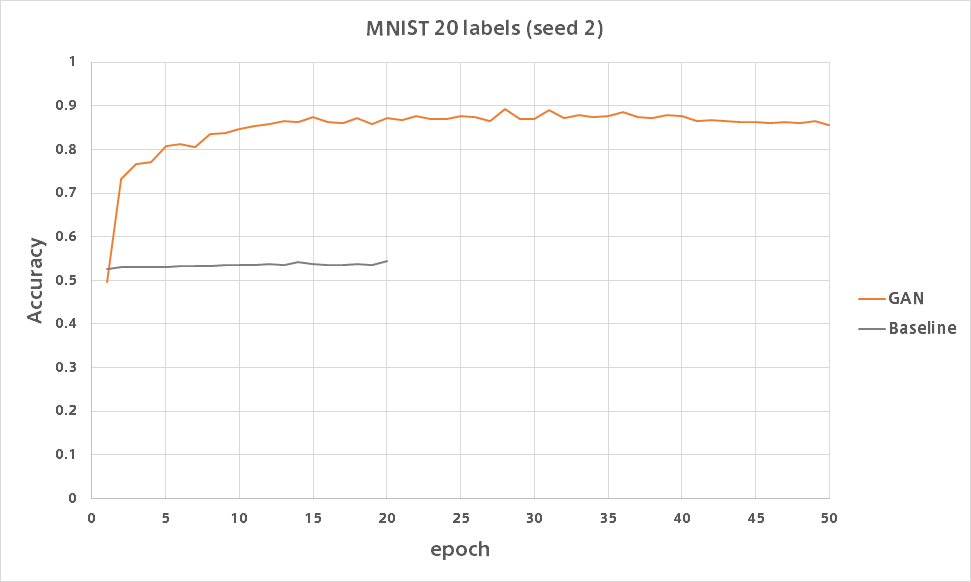
論文で報告されている精度が出ました。
VAT
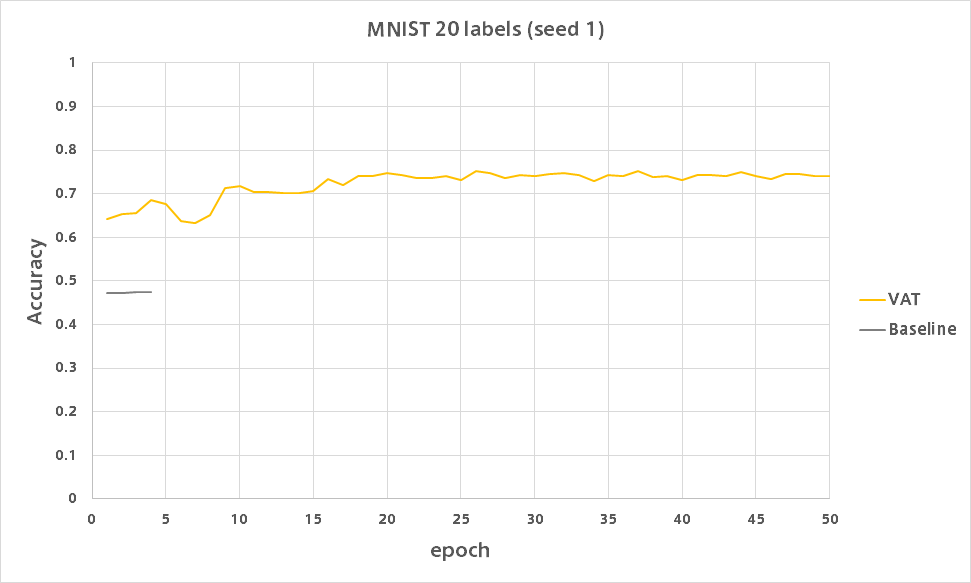
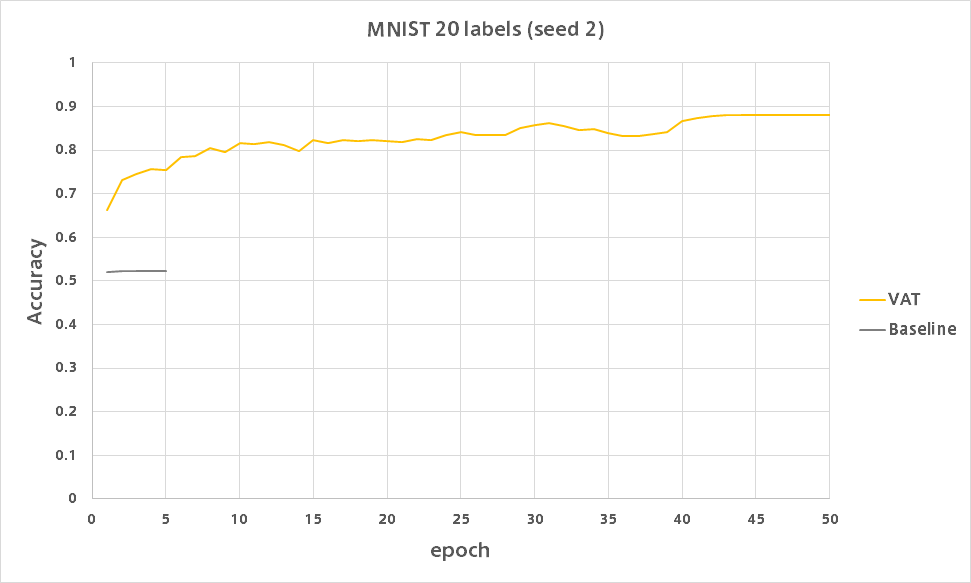
10ラベルのときとは違い精度が出ています。
SDGM
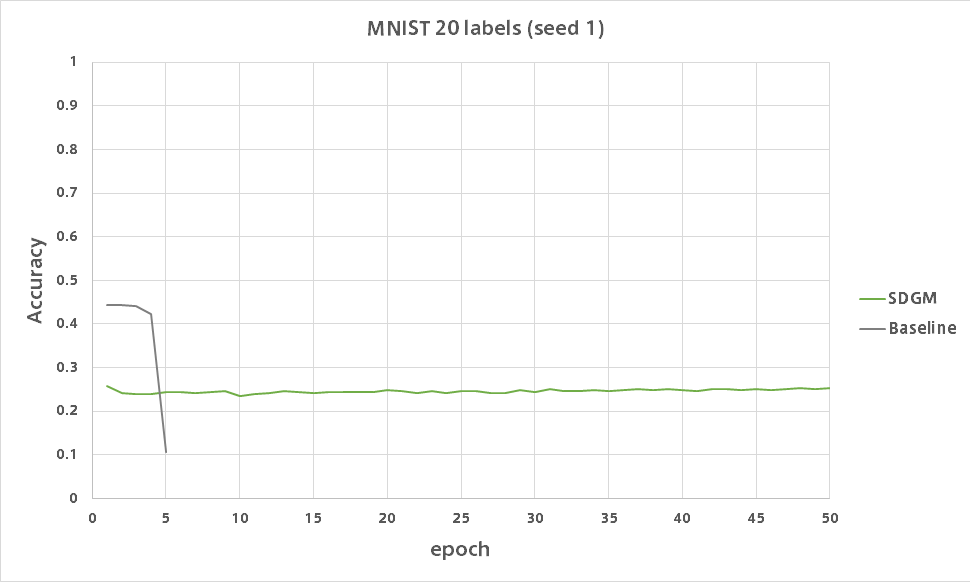
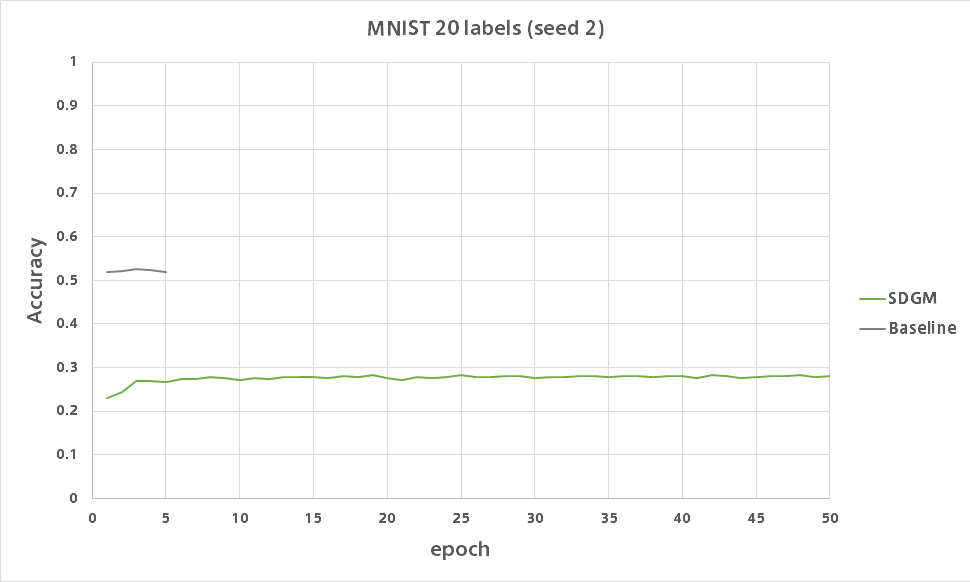
全然だめです。
AAE
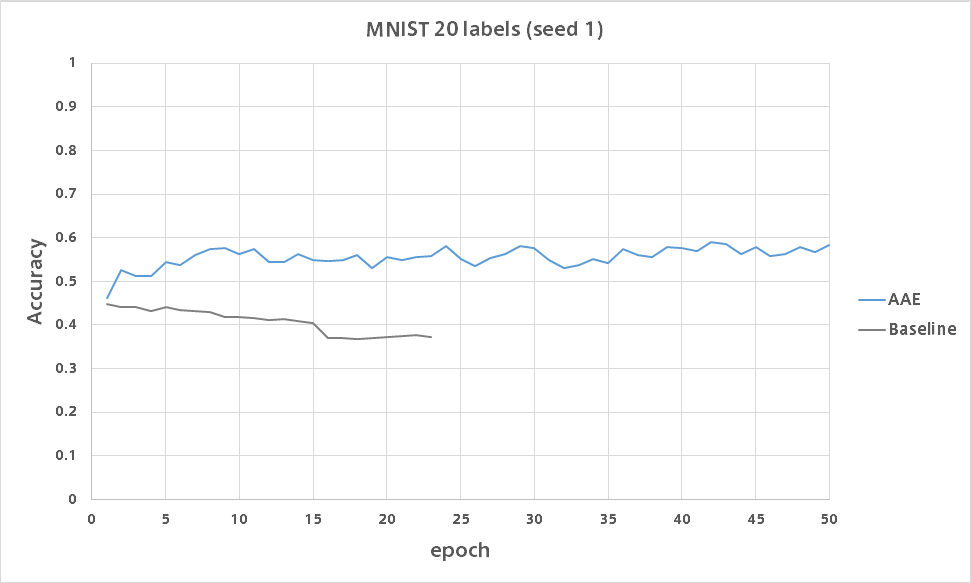
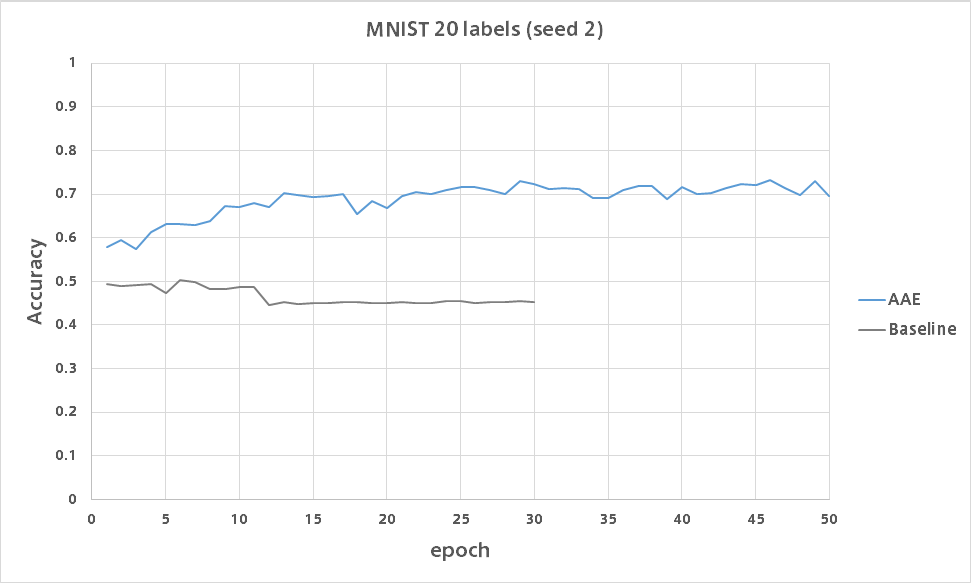
比較
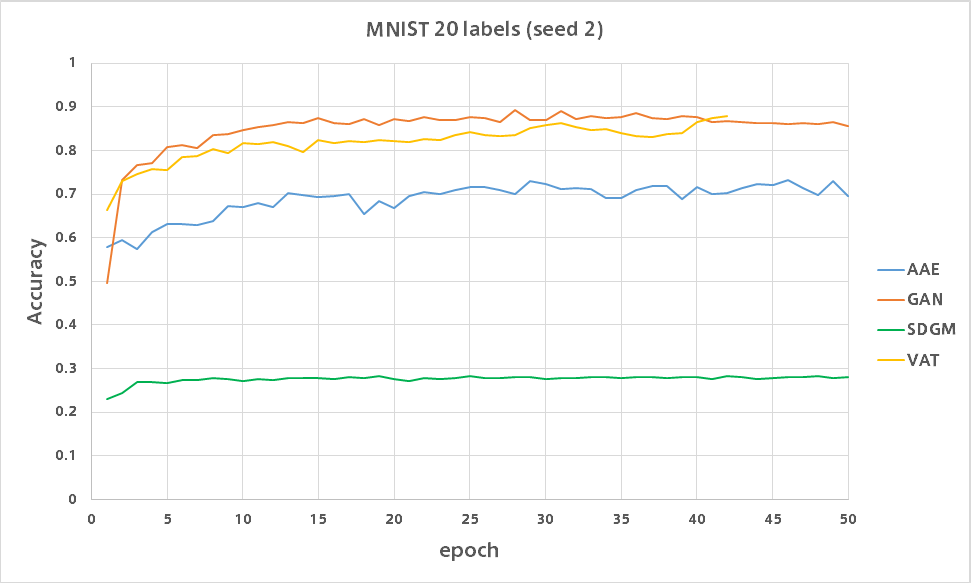
50ラベル
各数字につき5枚だけに正解ラベルを与えます。
時間がなかったのでまとめました。
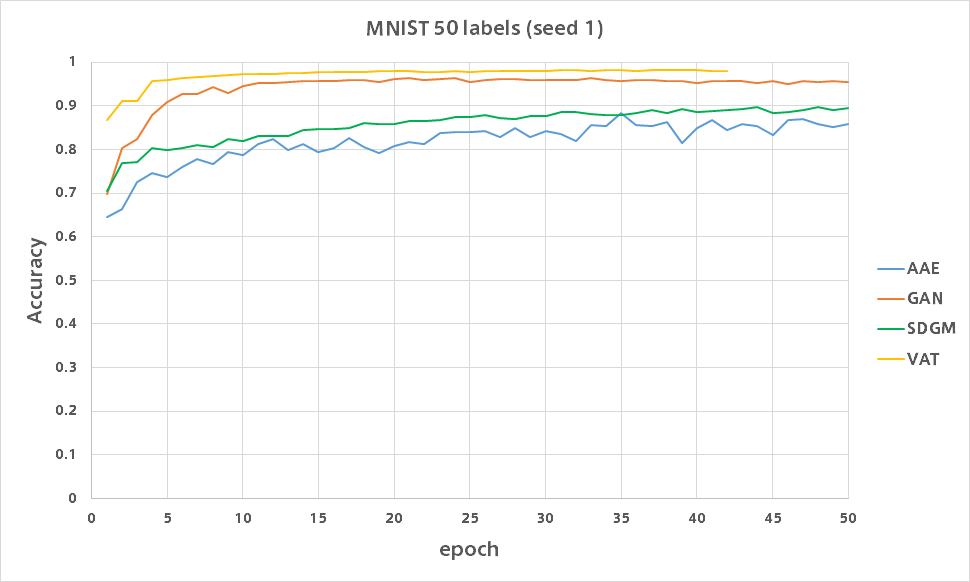
どのモデルも85%を超えています。
計算時間
実行速度はAAE = GAN > VAT > SDGMです。
VATは誤差逆伝播の回数が増えるため仕方がありません。
SDGMは単純にパラメータが多すぎです。(ネットワークが5つ必要です)
おわりに
GANが強すぎることが分かりました。
GANによる半教師あり学習については以前の記事に書きましたが、ネットワーク構造はごく普通の多クラス分類器そのままです。
そこにGeneratorを新たにネットワークを作って追加し、Discriminatorは追加のネットワークを使わず分類器の出力を上手く計算してデータが本物か偽物かを識別します。
そのためVATを組み込んだりと応用範囲が広い予感がするので今後注目していきたいと思います。
ちなみにVATは今まで作ってきた半教師あり学習の中では異常なくらい収束が早いです。
100ラベルの場合数分回すとシードによらず98%を超えます。
関連
- Learning Discrete Representations via Information Maximizing Self Augmented Training
- MNISTを98%の精度で分類できる手法です