
Deep Reinforcement Learning with Double Q-learning [arXiv:1509.06461]
概要
- Deep Reinforcement Learning with Double Q-learning を読んだ
- Double DQNをChainerで実装した
- DQNと比較した
はじめに
今回の論文は Double Q-learning をもとに DQN を改良したものになっています。
Double Q-learningの方は時間がなくてあまり読めていません。
実装
今回も実装にはChainerを使います。
実装と言ってもDQNのコードを数行書き換えるだけなので、前回実装したものをベースにしました。
前処理などは 前回の記事 と全く変わっていません。
具体的な変更点ですが、まずQ学習では以下の更新式により状態行動関数Qを更新します。
\[\begin{align} Q_{\theta}(s,a)\gets Q_{\theta}(s,a)+\alpha(r+\gamma \max_{a'}Q_{\pi}(s',a')-Q_{\theta}(s,a)) \end{align}\]ここでは状態$s$で行動$s$を取り、報酬$r$と次の状態$s’$を得たとしています。
$Q_{\theta}(s,a)$はパラメータ$\theta$を持つニューラルネット(DQNでは畳み込みニューラルネット+全結合層)です。
$Q_{\pi}(s,a)$は教師信号出力用のニューラルネットで、$Q_{\theta}(s,a)$のコピーになっています。(詳細は前回の記事)
式((1))は$Q_{\theta}(s,a)$を\(r+\gamma \max_{a'}Q_{\pi}(s',a')\)に近づける働きがあるため、教師あり学習とみなすことができます。
そこでDQNでは教師信号$target$を以下のように定義します。
\[\begin{align} target\equiv r+\gamma \max_{a'}Q_{\pi}(s',a') \end{align}\]Double DQNではこの$target$を以下のように変更します。
\[\begin{align} target\equiv r+\gamma Q_{\pi}(s',\argmax_aQ_{\theta}(s',a)) \end{align}\]DQN(式((2)))では、次状態$s’$のもとで取るべき最善の行動の評価値\(\max_{a'}Q_{\pi}(s',a')\)を用いて$Q_{\theta}$を更新していました。
つまり、次に取るべき行動の選択とその評価を同じ$Q_{\pi}$を用いて行っています。
一方Double DQN(式((3)))では、まず次状態$s’$で取るべき行動$a$を\(argmax_aQ_{\theta}(s',a)\)により決定し、その$a$の評価値$Q_{\pi}(s’,a)$を用いて$Q_{\theta}$を更新します。
こうすることで、次に取るべき行動の選択を$Q_{\theta}$で行い、その評価を$Q_{\pi}$で行うことになります。
この手法はDouble Q-learningの応用ですが、どうやらパラメータの違う2種類のQ関数を用いることで性能が上がるそうです。(まだ読めていないのでなんとも言えませんが)
実際に動かしてみる
必要なもの
- Arcade Learning Environment(ALE)
- エミュレータであり、ゲームを起動し後述のRL-Glueと接続してくれます。強化学習で言うところの環境とエージェントです。
- RL-Glue
- ALEで起動したゲームの操作をプログラムから行えるようにするものです。
- どうやら.debの方をインストールすると失敗するみたいなのでソース(3.04.tar.gz)を落としてコンパイルする方が良いみたいです。
- PL-Glue Python codec
- RL-GlueをPythonで使えるようにするものです。
- Atari 2600 VCS ROM Collection
- ブロック崩しやインベーダーなどのROMです。
- double-dqn
- 今回実装したDouble DQNのコードです。
- Chainer 1.6
- 古いバージョンのChainerで動くかどうかはわかりません。
環境構築に関しては DQN-chainerリポジトリを動かすだけ が参考になります。
実験
今回も例によってDouble DQNにAtari Breakoutをプレイさせます。
ダウンロードしたROMにはBreakoutが2つ入っており、片方は画面サイズがALE非対応のため起動できなくなっています。
起動できる方をbreakout.binにリネームしておいてください。
ターミナルを4つ起動し、以下をそれぞれのターミナルで実行します。
rl_glue
cd path_to_double-dqn
python experiment.py --csv_dir breakout/csv --plot_dir breakout/plot
cd path_to_double-dqn/breakout
python train.py
cd /home/your_name/ALE
./ale -game_controller rlglue -use_starting_actions true -random_seed time -display_screen true -frame_skip 4 -send_rgb true /path_to_rom/breakout.bin
ALEの–send_rgb はtrueで構いません。falseにするとグレースケールのスクリーンを取得できますが、なぜかALEネイティブのグレースケール変換は不自然だったのでDouble DQN側で変換するようになっています。
実験に用いたコンピュータのスペックは以下の通りです。
| OS | Ubuntu 14.04 LTS |
| CPU | Core i7 |
| RAM | 16GB |
| GPU | GTX 970M 6GB |
残念ながらメモリが足りず論文通りのReplay Memory Sizeでは動かないので、サイズを10分の1にしました。
Atari Breakout
Breakoutはブロック崩しです。
合計46時間の学習(7600プレイ・95世代・479万フレーム)を行い、DQNとDouble DQNでどちらの性能が優れているかを調べました。
プレイ回数とスコアの関係:
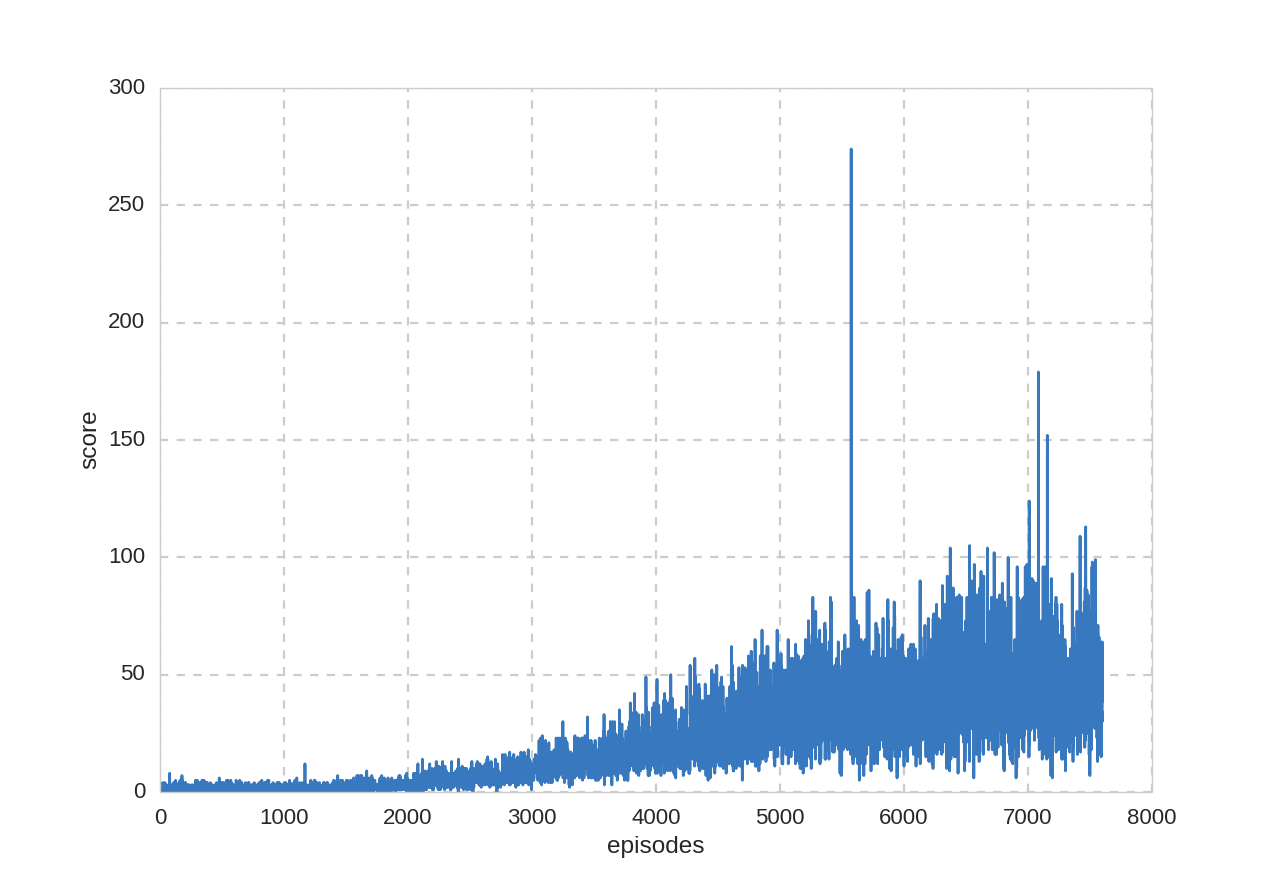
途中でとんでもないスコアを叩きだしていますが、おそらく偶然に背面を通す裏技を発見した可能性が高いです。(確認できませんでした)
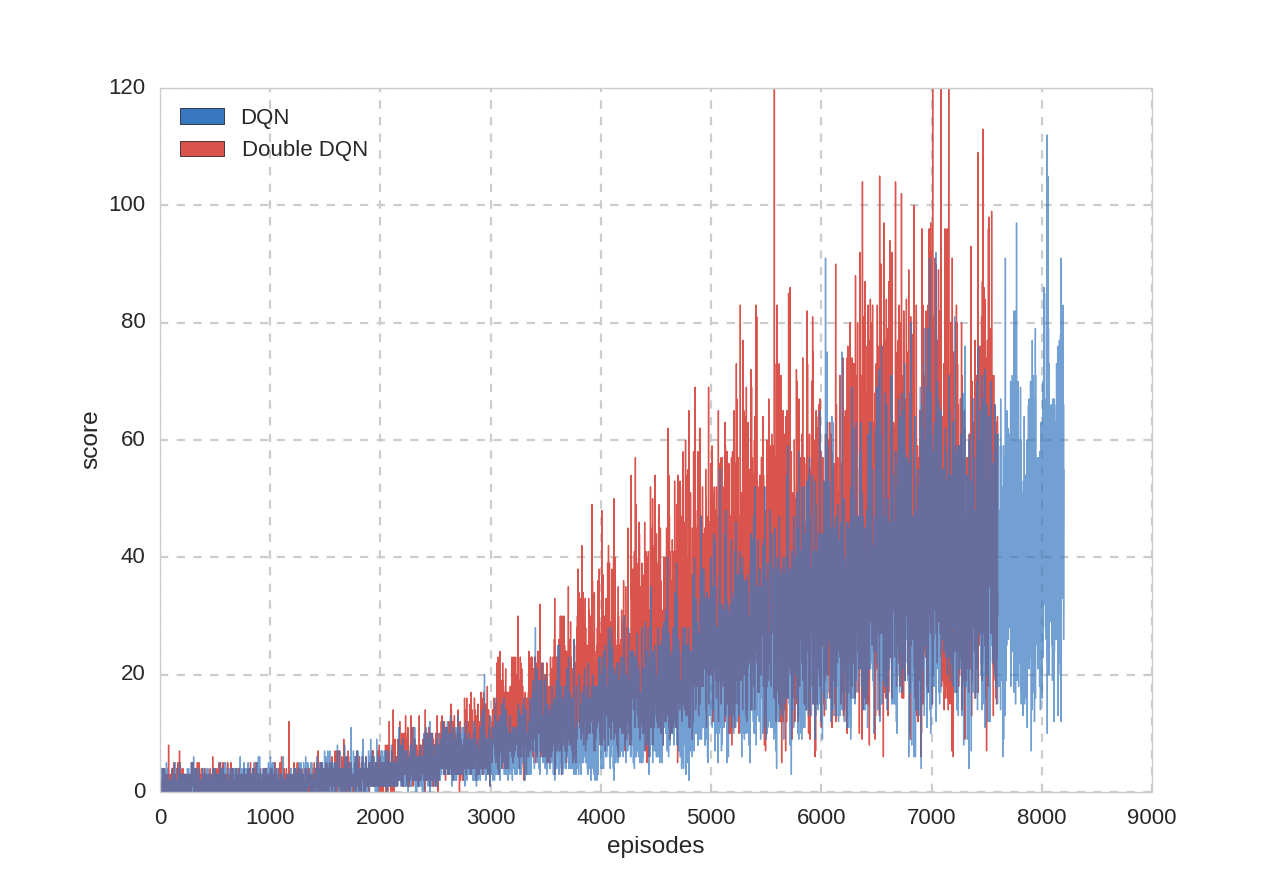
プレイ回数とハイスコア:
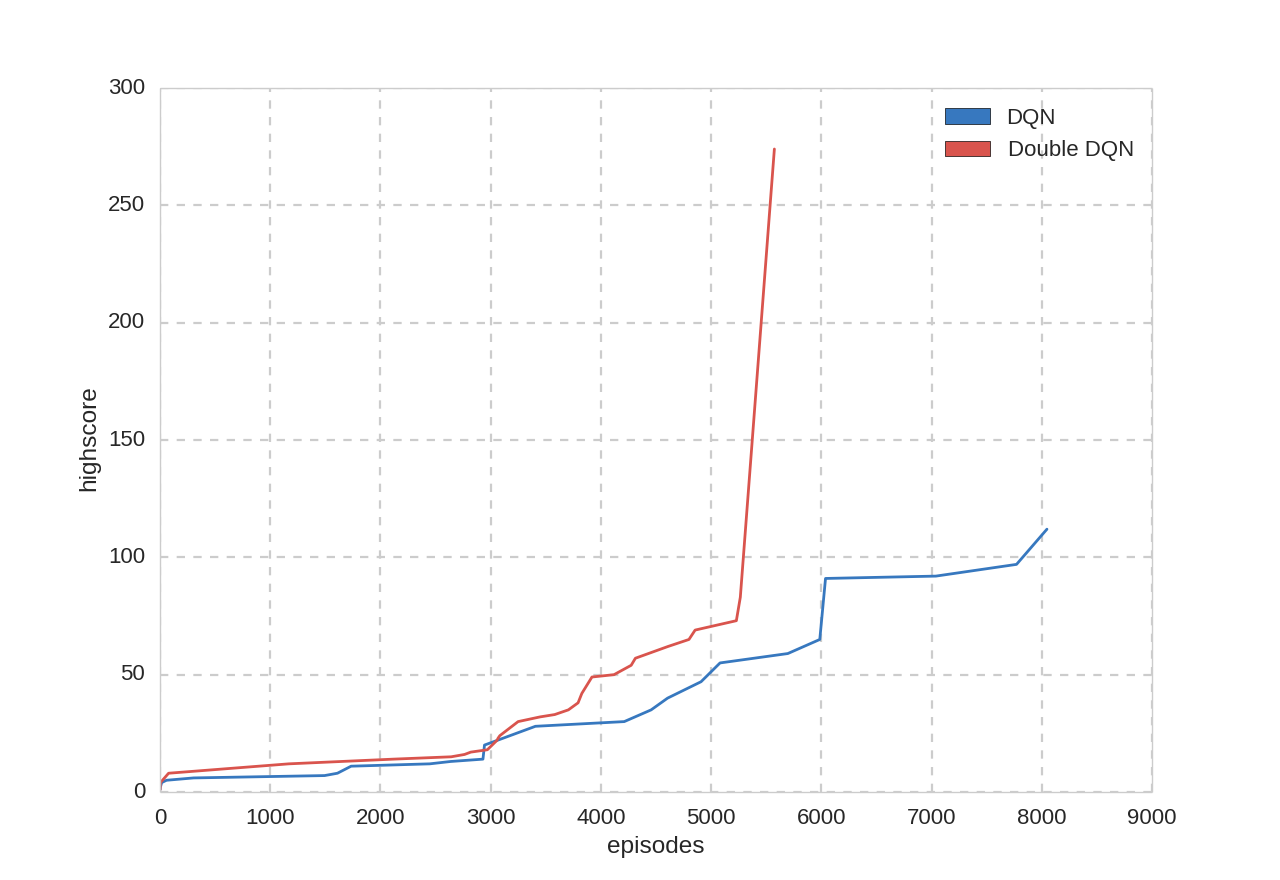
また、$\epsilon–greedy$手法の$\epsilon$を$0.05$に固定して評価を行いました。
学習100プレイごとに評価を20プレイ行い、スコアの平均を取りました。
平均スコア:
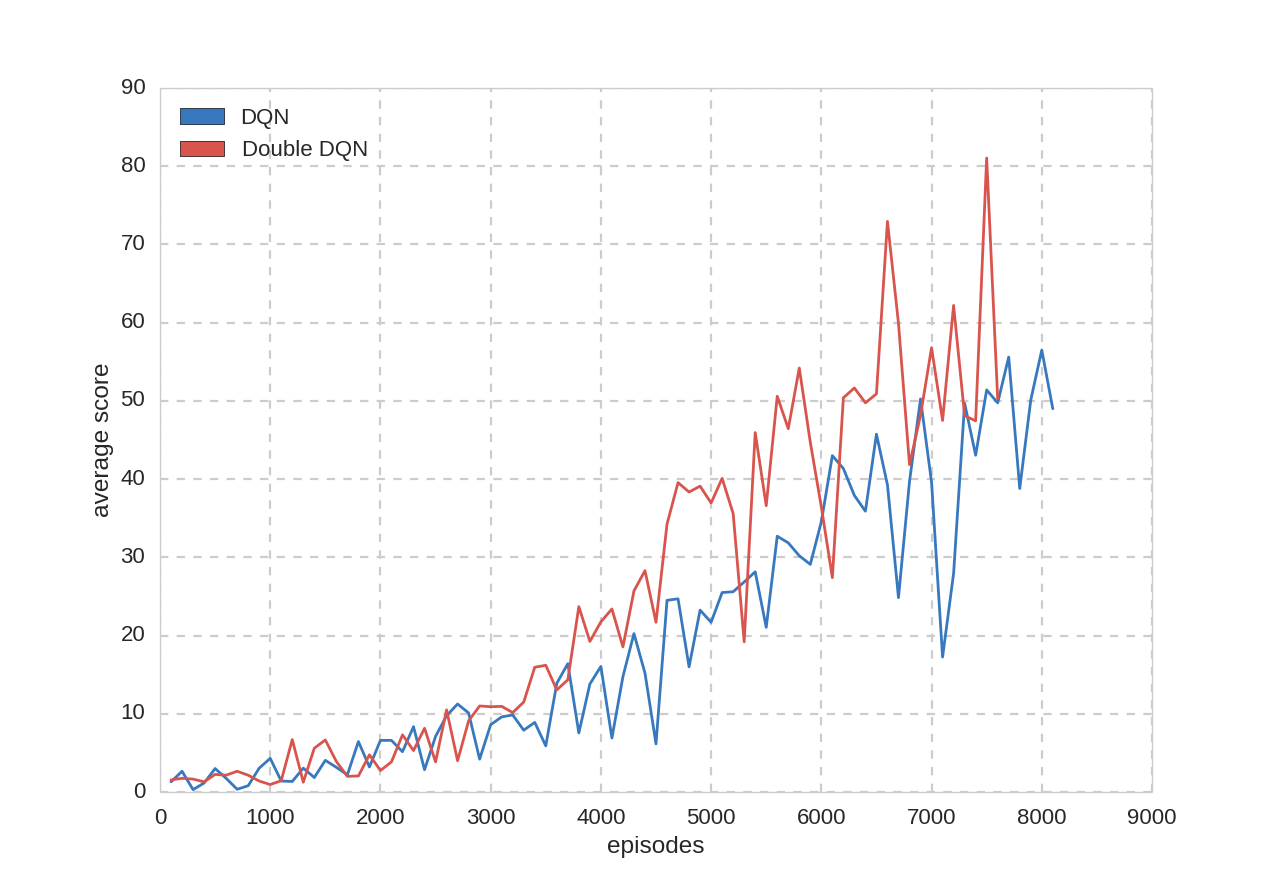
見た感じDouble DQNのほうが性能が良さそうですが、どの実験もすべて1回しか行っていないのでなんとも言えません。
1回実験を行うのに40時間くらいかかるのですが、DeepMindの発表によると数時間程度でスコア100を超えるそうなので、私の実装に何か不備があるとしか思えません。